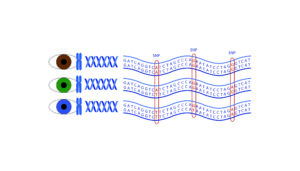
Kan vi bestemme forbryderens udseende ud fra et DNA-spor?
Forstil dig, at politiet finder et DNA-spor på et gerningssted. I dag kan politiet bruge DNA-sporet til at undersøge om det passer til en DNA-profil for en kriminel i politiets registre. Politiet kan også sammenligne en mistænkt persons DNA-profil med et DNA-spor fra forbrydelsen.
I fremtiden kan politiet bruge DNA-spor til at forudse forbryderens udseende, så udseendet kan bruges i opklaringsarbejdet. Man begynder at kunne forudse dele af et menneskes udseende ud fra DNA-materiale. Øjenfarve er en af de første karakteristika, man kan forudse.
Du har nok hørt om AI = Artificial Intelligens eller kunstig intelligens. I dette forløb vil vi vise dig et eksempel på, hvordan AI kan bruges. Machine learning (ML) er et bedre navn end AI. Machine Learning fortæller nemlig, at computeren lærer ud fra noget data og derefter forudser nyt.

I dette modul skal du lave en Machine Learning model, som kan forudse en persons køn. Du lærer hvordan it-systemer i dag kan trænes til at forudse forskellige ting ud fra nogle data.
Du skal
- undersøge Machine Learning modellen kNN sammen med dine klassekammerater
- se en video om Machine Learning
- installere programmet Orange
- se en video om programmering i Orange
- lave dit første Machine Learning program i Orange
- læse om bias i træningsdata og lave en øvelse om bias
 I begynder med en øvelse hvor alle i klassen deltager.
Når I har lavet klasseøvelsen skal du besvare spørgsmålene
I begynder med en øvelse hvor alle i klassen deltager.
Når I har lavet klasseøvelsen skal du besvare spørgsmålene
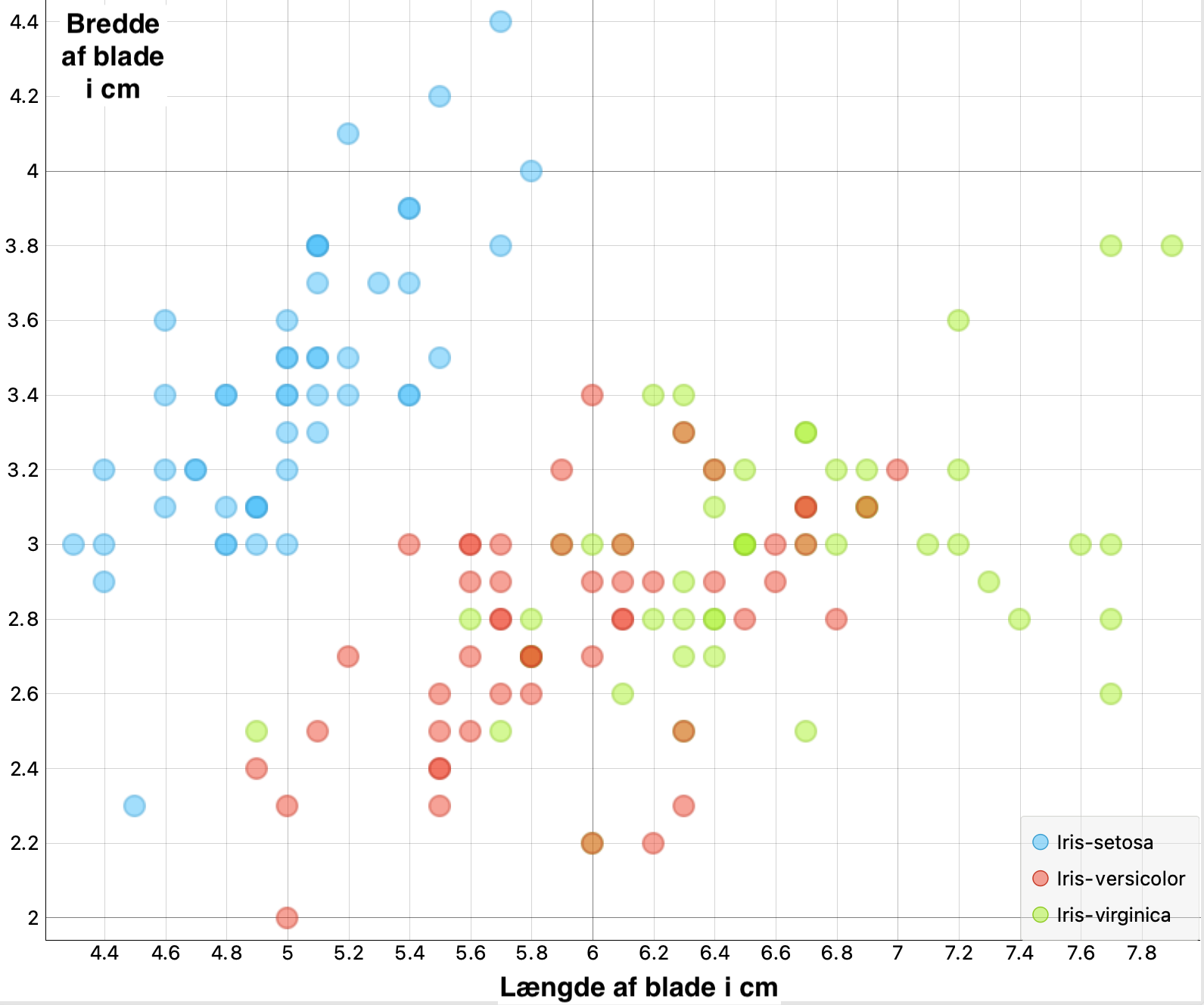
- Billedet illustrerer Machine Learning modellen k-Nearest-Neighbors (kNN). Et blad af en iris-blomst har længden 4.8 cm og bredden 3.2 cm. Kan man forudse hvilken Iris-art det er vha. modellen?
- Billedet illustrerer Machine Learning modellen k-Nearest-Neighbors (kNN). Et blad af en iris-blomst har længden 6.8 cm og bredden 3.2 cm. Kan man forudse hvilken Iris-art det er vha. modellen?
- Hvad står k for i k-Nearest-Neighbors?
Problemer med afspilning af videoen: Klik her
Forstå lighederne mellem lineær regression og en Netflix’s algoritmer
I videoen får du forklaret nogle vigtige begreber om Machine Learning. Du kender det måske som AI eller kunstig intelligens. Læg mærke til:
- Machine Learning (ML) – og forskellen mellem almindelige computerprogrammer og ML
- Træningsdata
- Forudsigelse
Installer programmet Orange
Programmet Orange hentes her Installer Orange på din computerPå mac
- Download programmet
- Åben dmg-filen i din overførselsmappe
- Træk Orange ikonet til din Applications mappe
På Windows
- Download programmet
- Åbn Orange Setup-programmet og følg instruktionerne – check på billederne nedenfor, hvad du skal vælge
- Vælg: “Install for anyone using this computer”
- Accepter “installation af required packages” – også Anaconda
- Tryk “Next” ved de næste step af installationen
- Afslut Setup-programmet
 Åbn programmet Orange – der ligger en video om “import af data” i værktøjskassen nederst i kurset.
Åbn programmet Orange – der ligger en video om “import af data” i værktøjskassen nederst i kurset.
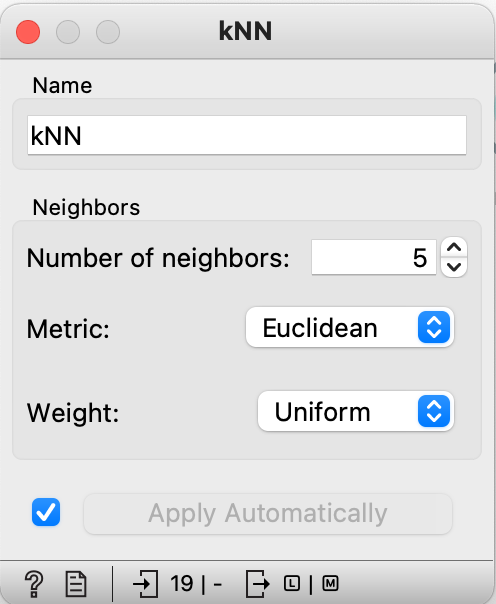
Opgave: Hent data ind i Orange
- Download datasæt (CSV-format): “HoejdeSko“. Du skal højre-klikke på linket, så du får muligheden for at hente filen ned på din computer.
- Tilføj “CSV File Import” til dit workflow – du finder ikonet til venstre i paletten “Data”
- Dobbelt klik på “CSV File Import” – klik derefter på mappen med de tre prikker
- Find filen “HoejdeSko.csv” på din computer
- Vælg “Semicolon” ud for “Cell delimiter” – tallene placeres nu i 3 kolonner
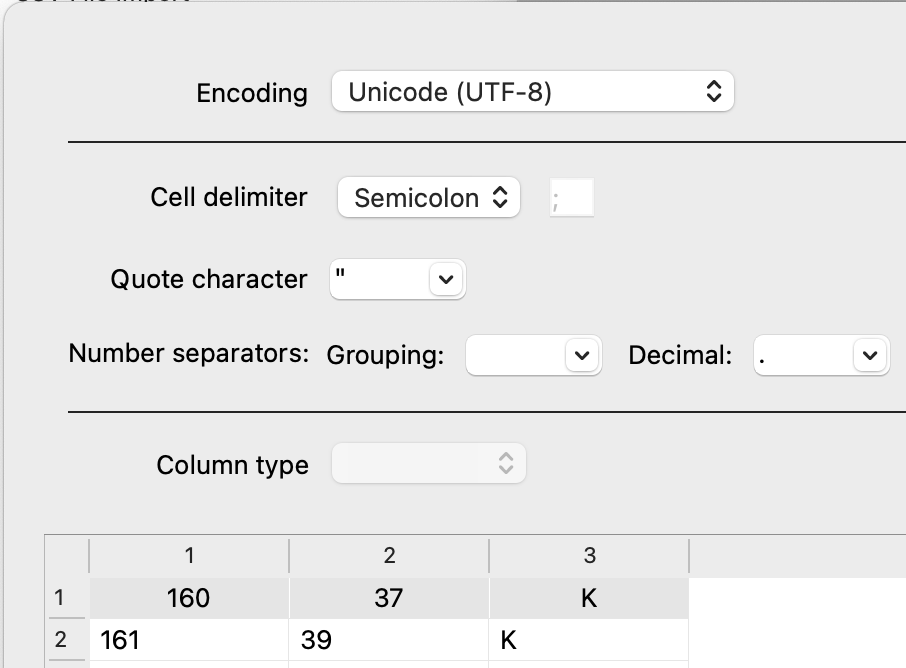
- Klik “Ok” – og luk vinduet “CSV File Import”
Opgave: Vis de importerede data
- Tilføj “Scatter Plot” fra paletten “Visualize”
- Forbind “CSV File Import” til “Scatter Plot”
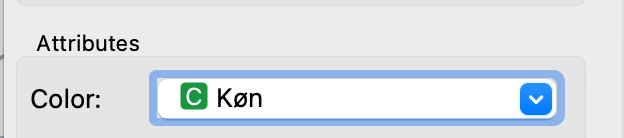
- Dobbelt klik på “Scatter Plot” – nu kan du se data i et plot og vælge, hvordan du vil undersøge data. Du kan vælge hvilke egenskaber som vises som x- og y-værdier. Prøv at sætte “Color” eller “Label” til Køn.
- Undersøg de importerede data og besvar spørgsmålene: – Hvilken skostørrelse har den mand, som har den største skostørrelse? – Hvilken højde har den højeste kvinde?

Forudse kategorier
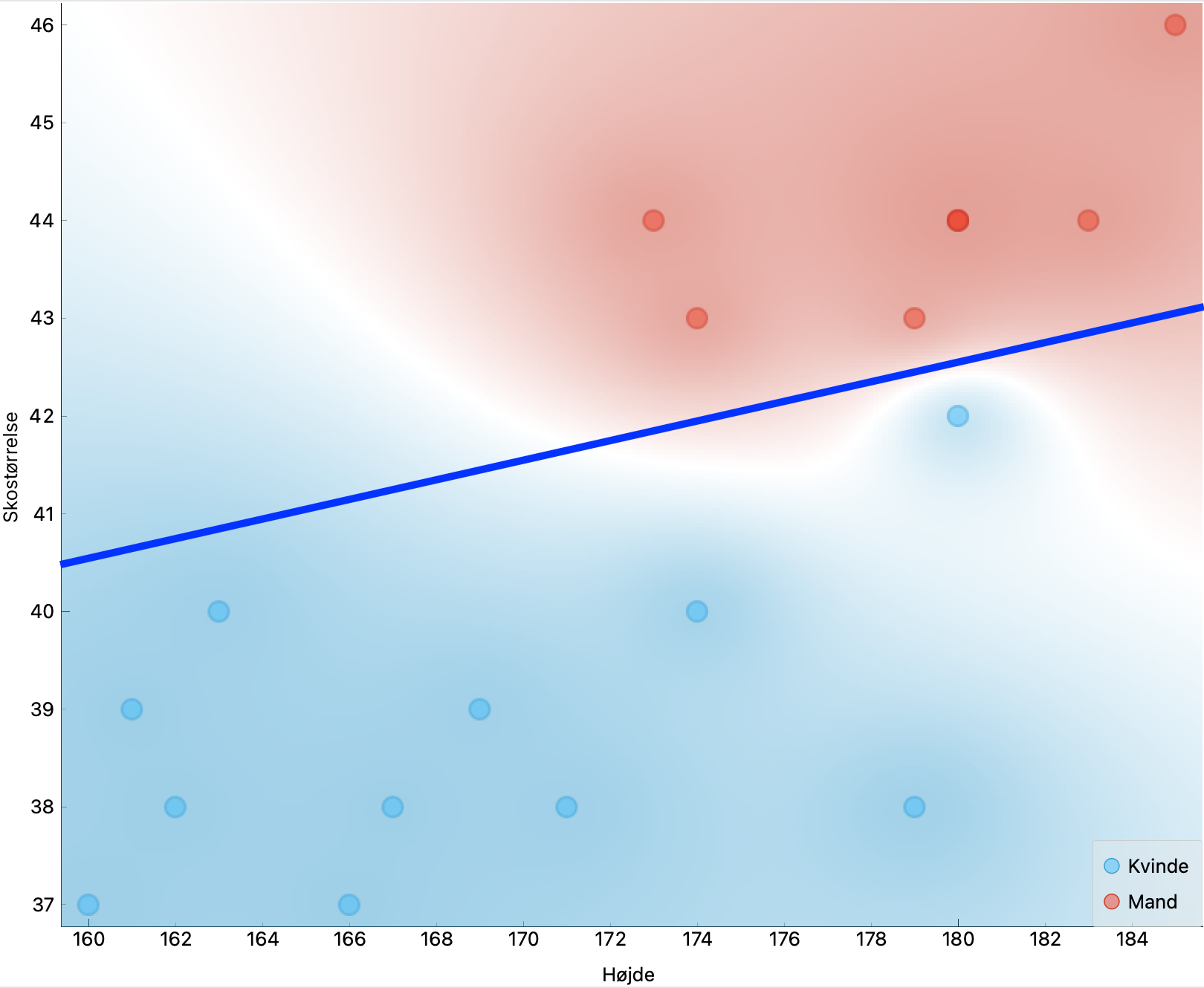
Ofte træner man Machine Learning modeller til at forudse om en person eller en ting passer i en bestemt kategori. I denne øvelse træner vi modellen med data om højde og skostørrelse og vil derudfra forudse køn. Højde og skostørrelse er egenskaber (Engelsk: features). Kønnet er den kategori, vi bruger som mål (target) i træningen.Opgave: vælg features og mål
- Tilføj “Select Columns” fra paletten “Transform”

- Forbind “CSV File Import” til “Select Columns”
- Dobbelt klik på “Select Columns”
- Check, at de data, du vil bruge som input til forudsigelserne, står under features.
- Flyt “Køn” til “Target” – da det er køn du vil forudse med modellen
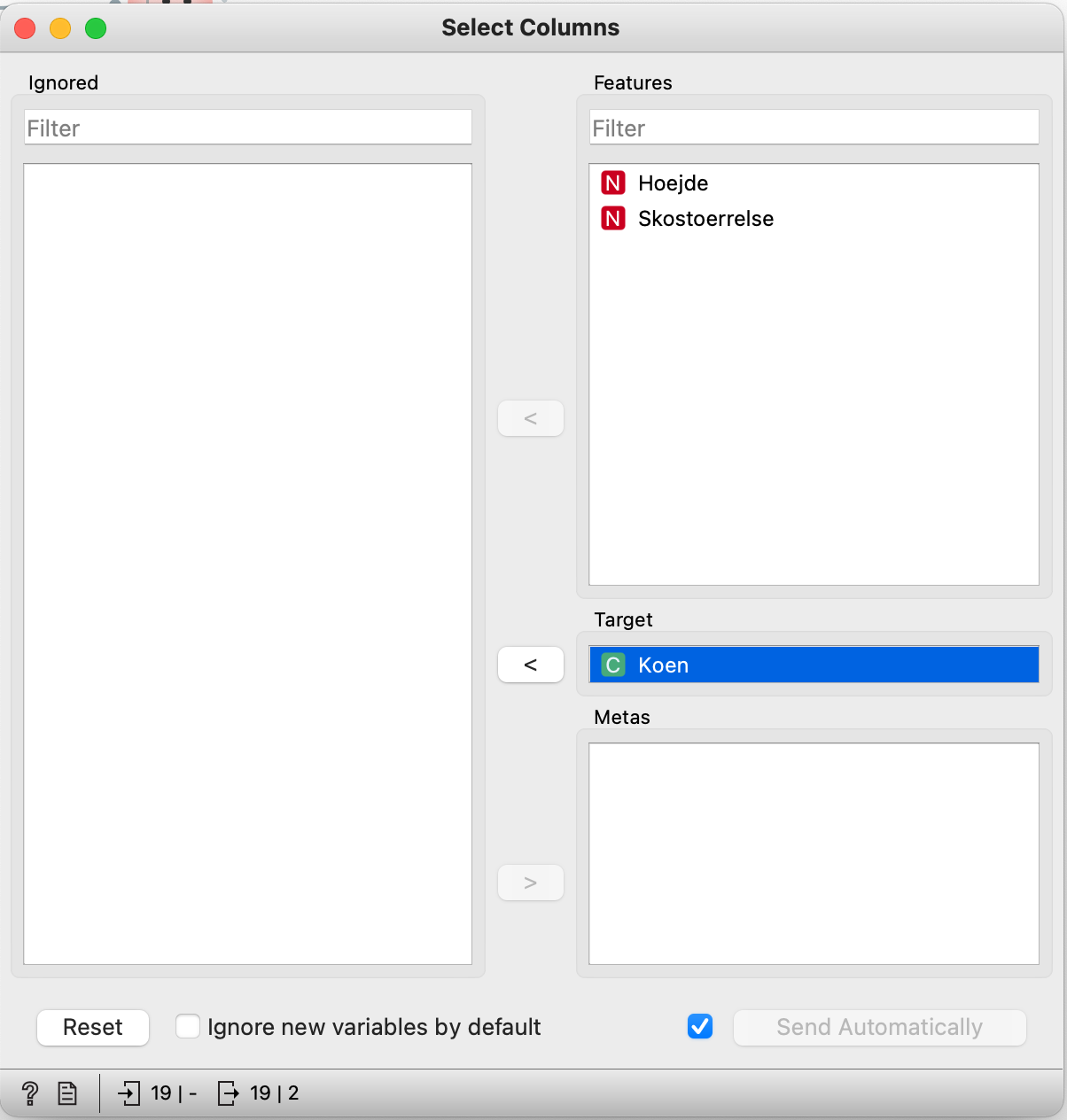
- Luk vinduet igen
Machine Learning modeller
Udtrykket kunstig intelligens eller Machine Learning dækker over mange forskellige modeller. Nogle modeller er gode til at genkende ting på billeder, andre egner sig til at forudse, om vi vil vælge en film, klikke på en nyhed, eller forudse vores køn. Modellen k-Nearest-Neighbors (kNN) er ofte god til at klassificere ting, når man kender nogle numeriske egenskaber for tingene. I dette eksempel prøver vi at forudse kønnet ud fra højde og skostørrelse med en kNN-model. Support Vector Machine (SVM) og Decision Tree (Tree) er andre modeller, som også kan bruges til at klassificere ting. Neurale Netværk er en ML-model, som ofte bruges til at genkende billeder eller tolke håndskrift.Opgave: Vælg ML-model
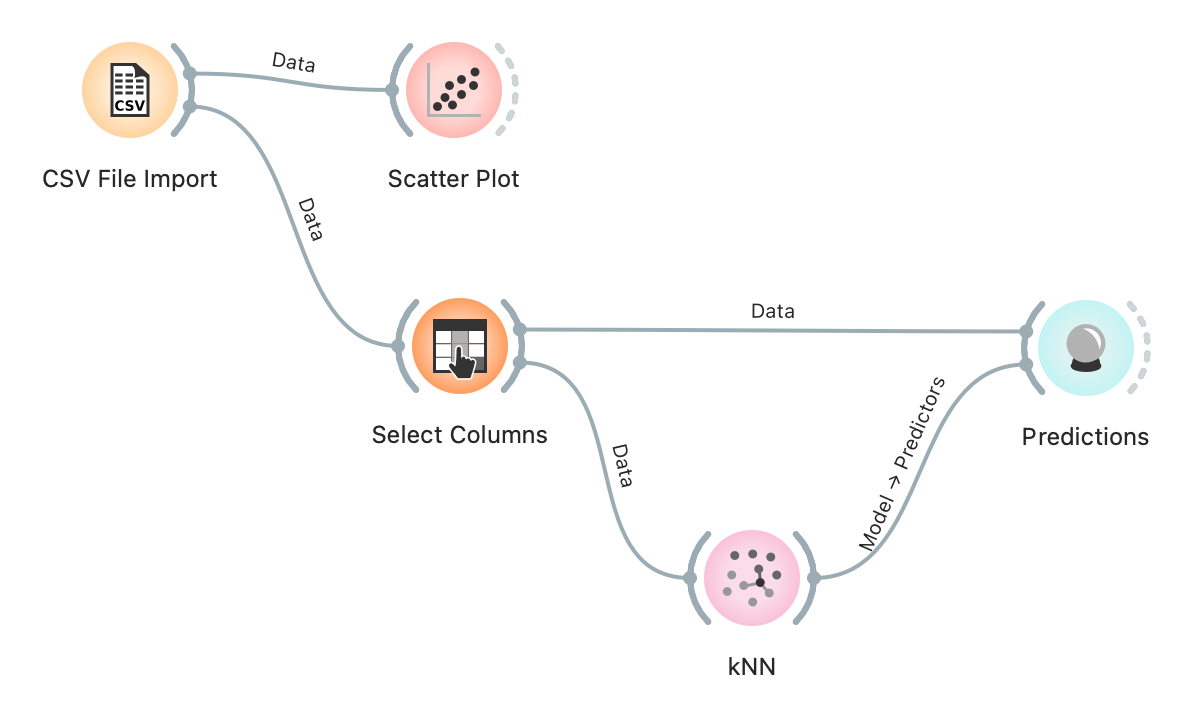
- Tilføj “kNN” fra paletten “Model” – det er modellen k-Nearest-Neighbors
- Forbind “Select Columns” til “kNN”
- Dobbelt klik på “kNN”
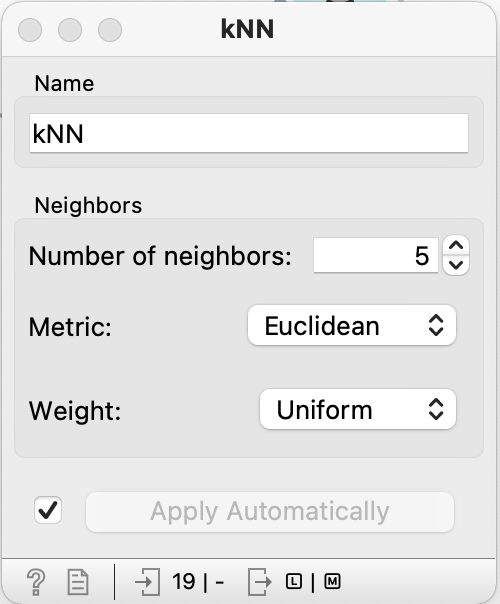
- Nu skal du vælge antallet af nærmeste naboer, som du vil bruge til at forudse, kønnet for en ny elev med nye værdier for højde og skostørrelse – normalt vælger vi 3 eller 5 naboer
- Vi skal også vælge “Metric” dvs. den måde vi måler afstande – normalt afstandsmål er Euclidean – det svarer til det du kender fra matematik \(d=\sqrt{(x_2-x_1)^2+(y_2-y_1)^2}\)
- “Weight” vælges til “Uniform” – så vægter det valgte antal naboer (fx 5) lige højt, når kønnet for en ny elev skal bestemmes. Alternativet er “Distance” – hvor de naboer der er tættest på vægtes højere i bestemmelse af kønnet for en ny elev.

Tag et skærmbillede af dit workflow i Orange, hvor man kan se, hvordan dit program ser ud nu. Sæt billedet ind i dine noter, så du kan finde tilbage til hvordan programmet så ud, og du kan vise det til din lærer.

Først træner man, derefter tester man modellen
I afsnittet “1.2.4 – Vælg ML-model” har du trænet din kNN-model med et træningsdatasæt. Det gør Orange automatisk, når du forbinder træningsdata til en ML-model. Nu skal du teste, hvor god modellen er til at forudse køn. Man måler hvor mange gange modellen laver den rigtige forudsigelse i forhold til antallet af forudsigelser \(\frac{Antal\ rigtige}{Antal\ test}\). På engelsk kaldes det accuracy (AUC) og angives som et decimal tal eller i %. Modellen vil altid være bedst, når man tester den med nogle data, som ligner træningsdatasættet. Vi starter derfor med at teste med de samme data, som vi brugte til træning af kNN-modellen.Sådan skal workflowet se ud, inden du går videre til næste opgave
Opgave: Test din kNN-model
- Tilføj “Predictions” fra paletten “Evaluate”
- Forbind “kNN” til “Predictions”
- Forbind “Select Columns” til “Predictions”
- Dobbelt klik på “Predictions”
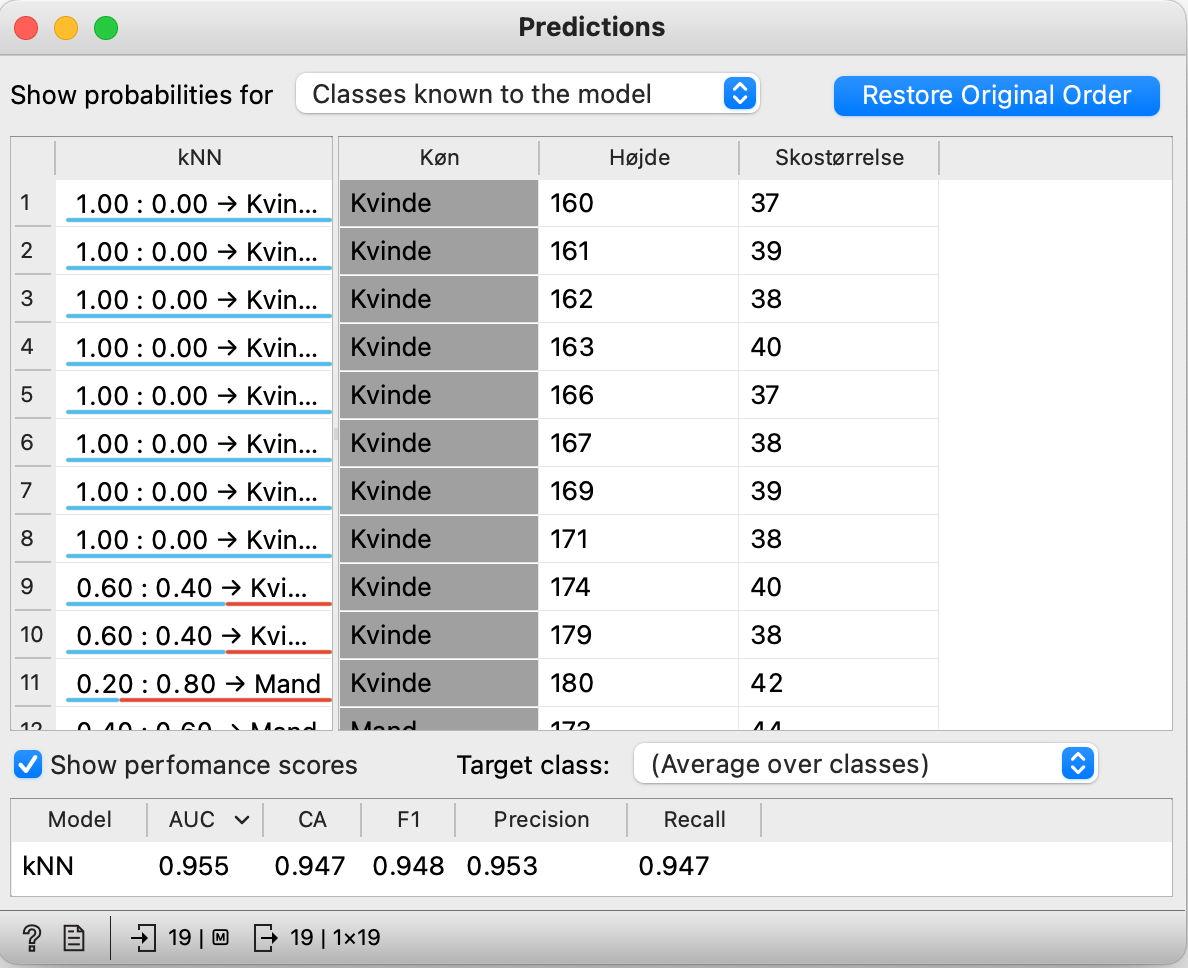
- Vælg “Classes known to the model” ud for “Show probabilities for”
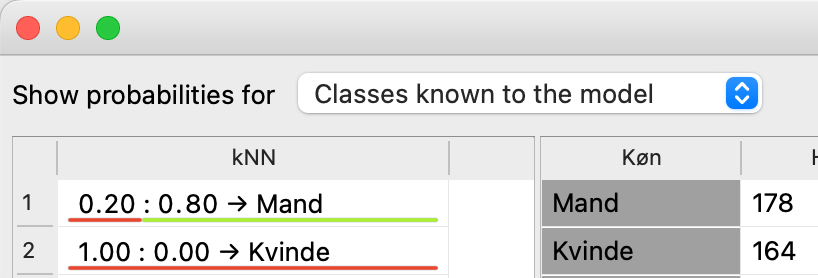
- Kolonnen kNN viser hvor sikker modellen er på forudsigelserne af køn.
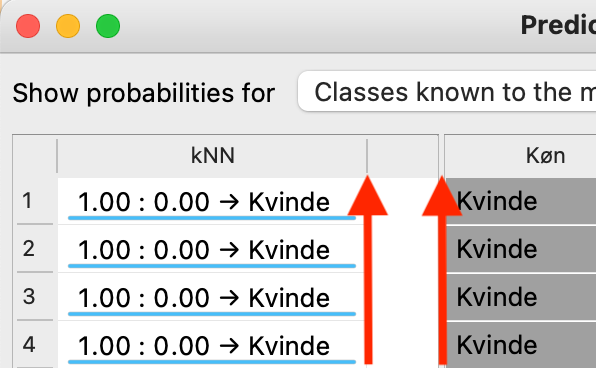
For at se alle detaljer, skal du gøre første kolonne bredere. Træk der hvor pilene peger
- I linje 9 kan man se, at modellen med 60%-sikkerhed forudser, at en person på 174 cm med skostørrelse 40 vil være en kvinde. Modellen angiver samtidigt 40%-sikkerhed for, at det er en mand. Derfor forudser modellen, at denne person er en kvinde.
- Hvor mange personers køn forudses forkert i denne model?
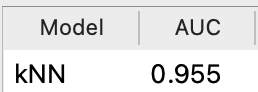
- Nederst i vinduet er der nogle flere mål for modellens evne til at lave rigtige forudsigelser. AUC beregner, hvor god modellen er til at lave rigtige forudsigelser. Når det er bedst, er AUC = 1. Gætter den altid forkert er AUC = 0.

Optimering af Machine Learning modeller
Machine Learning modeller skal optimeres, så de virker bedst muligt. Det gør man ved at justere på modellens parametre. I kNN-modeller er det bl.a. antallet af naboer, man bruger. Bruger man 5 naboer, bestemmer flertallet af de 5 naboer, hvilken kategori det nye punkt tilhører. Hvis 3 naboer er kvinder og 2 er mænd, vil modellen forudse, at det nye punkt er en kvinde. Man kan også justere måden man måler afstand (Metric) og om de nærmeste punkter vægter mere end punkterne længere væk (Weight).Opgave: hvor mange naboer skal vi bruge i kNN?
- Dobbelt klik på “kNN” – her ændrer du parametre til modellen
Derefter kan du se resultatet i “Predictions”
- Undersøg om modellen bliver dårligere eller bedre til at forudse køn ud fra højde og skostørrelse, når modellen bruger 1, 2, 3, 4 eller 5 naboer til at forudse kønnet.
- Undersøg om modellen bliver bedre ved at sætte “Weight” til “Distance“, når du bruger 5 naboer. “Distance” betyder, at naboer tæt på, vægter højere end naboer længere væk, når modellen skal forudse kønnet for et nyt datapunkt.
Opgave: Support Vector Machine
- Tilføj “SVM” fra paletten “Model”
- Forbind “Select Columns” til “SVM”
- Forbind “SVM” til “Predictions”
- Nu kan du sammenligne “kNN” med “SVM” i “Predictions” – dobbelt klik på “Predictions” og sammenlign AUC for kNN- og SVM-modellerne.
Testdata
Når modellen er optimeret, skal den testes igen med et helt nyt datasæt. Download datasættet (CSV-format): “HoejdeSko2” – Højre-klik og gem filen på din computer. Vi tester for at vide, hvordan modellen vil virke, hvis vi vil bruge den rigtigt.Opgave: test modellen med HoejdeSko2-datasættet
- Tilføj en ny “CSV File Import” fra paletten “Data”
- Indlæs den nye fil
- Tilføj en ny “Select Columns” fra paletten “Transform”
- Forbind den nye “CSV File Import” til den nye “Select Columns”
- Vælg “Køn” til “Target” i “Select Columns”
- Tilføj en ny “Predictions”
- Forbind “kNN” til den nye “Predictions“
- Forbind den nye “Select Columns” til den nye “Predictions“
- Dobbelt klik på “Predictions” og undersøg, hvor godt modellen virker.
Vælg “Classes known to the model” og check om AUC er bedre eller dårligere med det nye datasæt.

En ML-model bliver aldrig bedre end det data, man har brugt til at træne modellen med.
Bias i træningsdata
Bias henviser til menneskers fordomme og stereotype opfattelser om andre. I Machine Learning henviser bias til systematiske fejl, som f.eks. kan opstå fordi træningsdatasættet ikke repræsentere omverdenen præcist.
En gruppe af “midaldrende hvide mænd” beskriver kun en begrænset del af verdens befolkning. ML-modeller trænet med træningsdata, som kun repræsenterer en begrænset gruppe eller inkluderer egenskaber som favorisere en bestemt gruppe, vil give et meget skævt billede af den verden som modellen skal beskrive.
I denne opgave skal du kort beskrive et muligt problem, som dårligt valgte træningsdata kan skabe. Overvej:
- Hvad vil ML-modellen forudse forkert?
- Hvorfor vil ML-modellen forudse dette, dvs. hvilken bias er der i data?
Når du har beskrevet et problem, skal du bytte din beskrivelse med en holdkammerat. Du skal nu læse holdkammeratens beskrivelse af et bias-problem og skrive et forslag til en forbedring af data, så den omtalte bias kan undgås.
Mangler du inspiration, kan du se nogle flere anvendelse af Machine Learning her: AI: Impact on Society
Hjælpe politiet med at forudse 3 gerningsmænds øjenfarve
Forestil dig, at politiets efterforskere sender dig DNA-materiale fra 3 forskellige forbrydelser. Du har derefter behandlet DNA-sporene og undersøgt dem for mutationer, som bestemmer øjenfarven. Nu skal du lave en ML-model, der kan forudse gerningsmændenes øjenfarve.
DNA-fænotyping: fra DNA til gerningsmand
DNA-fænotyping er at bruge DNA til at forudsige, hvordan en person ser ud. Har politiet fundet et DNA-spor som ikke matcher tidligere gerningsmænd i deres database, kan de bruge DNA-fænotyping til at få information om gerningsmandens udseende. Det svarer til politiets fantomtegninger, men her laves tegningen ud fra DNA sporets information.
I dette modul skal du
- læse om hvorfor øjne har forskellige farver
- læse om forskellen på statistisk og Machine Learning
- lave et program i Orange
- træne din ML-model
- teste din ML-model
- forudse øjenfarven for de 3 DNA-spor, du har modtaget
- undersøge hvilke mutationer ML-modellen bruger til forudsigelser
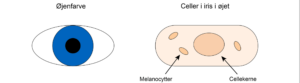
Melanin i øjnene bestemmer øjenfarven
Dit DNA bestemmer, hvor meget af farvestoffet melanin, der dannes i de forreste lag i din øjne. Der er flere gener, som koder for produktionen af melanin. Nogle mennesker har mutationer i de gener, som koder for melanin. Derfor har de nedsat eller ingen melanin i øjnene, og øjnene er grønne eller blå. I dette modul skal vi lave en Machine Learning model, som kan forudse øjenfarve ud fra mutationer i de gener, som styrer produktionen af melanin.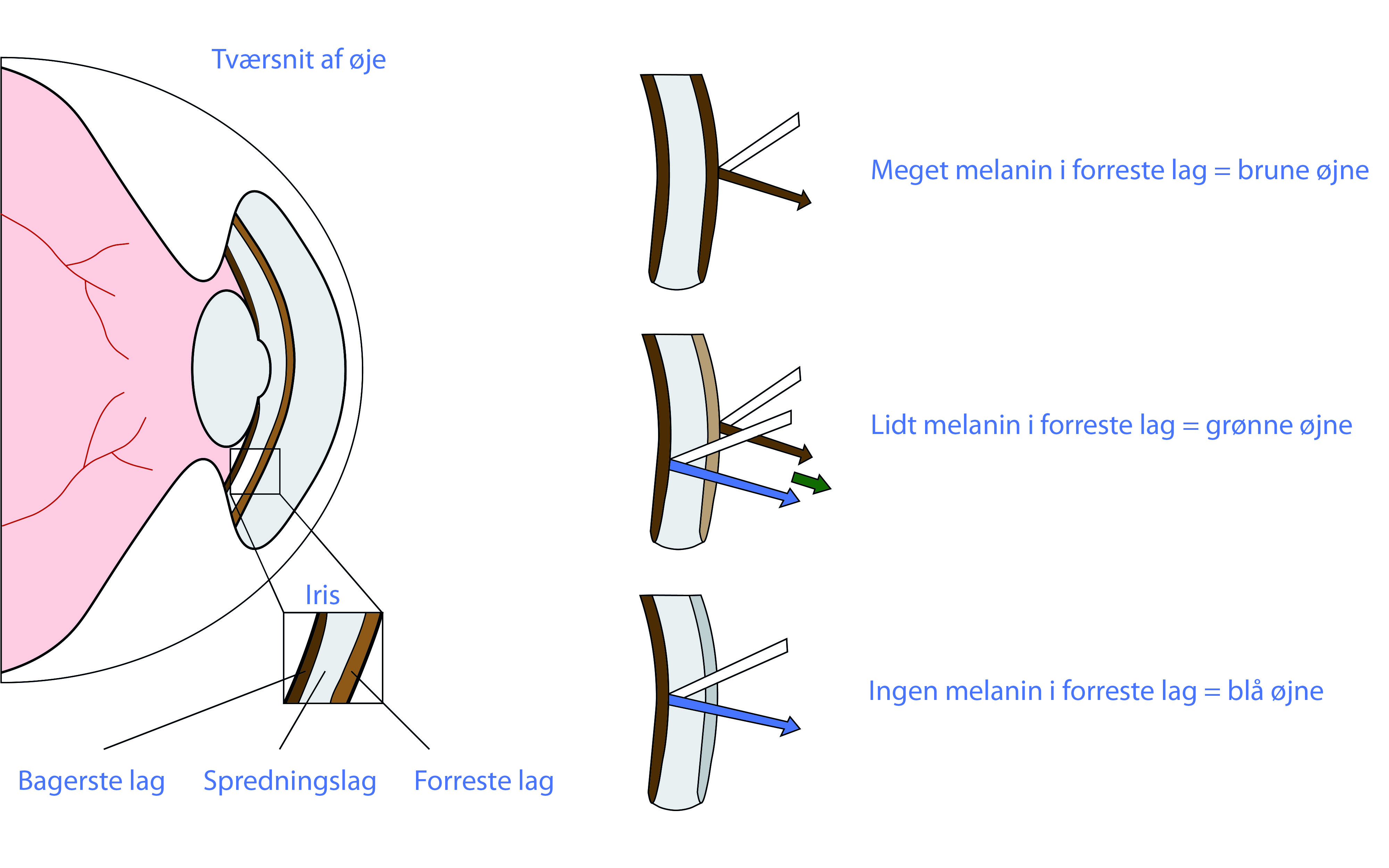
Vil du vide mere?Se videoen “Melanin og øjenfarve” i værktøjskassen – du finder den nederst i menuen til venstre |
I matematik har du lært at lave statistik. Du kan beregne gennemsnittet af kvinders højde eller lave et boksplot, som viser fordelingen af højder. Du kender også sandsynligheds regning, som du kan bruge til at forudse sandsynligheden for, at en tilfældig person er 172 cm høj eller har blå øjne.
Machine learning går skridtet videre. Her kan du ud fra nogle oplysninger om personen, forudse andre egenskaber. Computeren undersøger data om mange personer og laver en model ud fra data. Når modellen derefter fordres med data om en ny person, kan den f.eks. forudse personens øjenfarve..
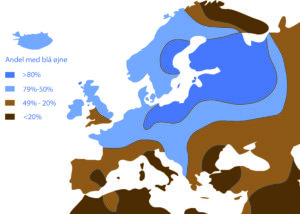
| Øjenfarve | Frekvens |
| Blå | 70% |
| Grøn | 14% |
| Brun | 16% |
Statistik
I statistik beskriver man data med frekvens, middelværdi, spredning og andre statistiske deskriptorer. F.eks. kan øjenfarven for befolkningen i Danmark beskrives i en tabel med frekvensen for hver øjenfarve.
Sandsynlighedsregning
Her kan vi besvare spørgsmål af typen:
- Hvor stor er sandsynligheden for, at en tilfældigt valgt person i Danmark har blå øjne?
- Hvor stor er sandsynligheden for, at en blåøjet mor og en brunøjet far får et blåøjet barn?
Svaret på det første spørgsmål er “sandsynligheden for at en tilfældigt valgt person har blå øjne er 70%”. Sandsynlighedsregning bygger ofte videre på statistikken. Man skal først observere mange personers øjenfarve = statistik, før man har en sandsynlighed for, at en persons øjenfarve er blå.
Korrelationer i statistik
Ofte undersøger man sammenhængen mellem 2 hændelser, f.eks. sammenhængen mellem mutationer i vores DNA og øjenfarve. Hvis alle eller næsten alle med blå øjne også har den samme mutation i DNA, siger man, at der er en sammenhæng. Sammenhængen kalder man en korrelation.
Korrelation forklarer ikke sammenhængen mellem hændelser. Kun at de to hændelser optræder hos de samme mennesker. Hvis mutation A giver blå øjne og mutation B giver lys hud, vil vi ofte se, at personer med blå øjne også har mutation B, selv om mutation B ikke påvirker øjenfarven.
Genome-wide association study (GWAS)
Søger man efter den genestiske årsag til en sygdom eller f.eks. øjenfarve, skal man først finde de DNA-mutationer, som optræder sammen med sygdommen. Man finder altså korrelationer (associations) mellem bestemte mutationer i DNA’et og den hændelse, at personen har en bestemt egenskab eller sygdom.
Korrelationerne hjælper med at finde de mutationer, som kan være årsag til sygdommen. Man skal derfor undersøge færre mutationer for at finde årsagen til sygdommen, da man kun behøver at undersøge betydningen af de mutationer, der optræder sammen med sygdommen.
Med resultaterne fra GWAS kan man igen svare på sandsynlighedsspørgsmål, f.eks. hvor stor er sandsynlighed for, at en tilfældig person med mutation A, B og C har blå øjne.
Machine Learning
I Machine Learning (ML) går vi skidtet videre. Med Machine Learning vil vi gerne kunne forudse om en bestemt person har en bestemt sygdom eller en bestemt egenskab f.eks. øjenfarve. I ML træner man en ML-model på en computer med DNA-data for nogle personer, hvor øjenfarven også er kendt.
Efter træning af ML-modellen, kan den forudse en persons øjenfarve, når ML-modellen får DNA-data om en person. Finder politiet et DNA-spor fra en gerningsmand, kan man derfor forud se gerningsmandens øjenfarve f.eks. blå øjne og dermed udelukke alle mistænkte med brune øjne.
ML-modeller kan bruge mange forskellige metoder. Nogle metoder kan vi forstår og i princippet regne efter i hånden. Det gælder kNN og SVM, som vi brugte i 1. modul. Andre ML-modeller kalder vi black-boks, fordi vi ikke kan forstå præcis, hvordan ML-modellen når frem til resultaterne ud fra træningsdata. Det gælder f.eks. Neurale netværk.
Vil du vide mere om Machine Learning og Neurale netværk?Elements of AI tilbyder et gratis online kursus, hvor du bliver introduceret til Machine Learning. På 3blue1brown kan du få forklaret, hvordan et neuralt netværk genkender håndskrevne tal |
Vil du vide mere om Genome Wide Association Study og analyse af DNA?Se videoen Genome Wide Association Study i værktøjskassen – du finder den nederst i menuen til venstre. |

Opgave 1
Svar på følgende spørgsmål:
- Hvilken øjenfarve har du?
- Hvilken hårfarve har du?
- Er dine øreflipper fastgroede eller frie?
- Er du højrehåndet, venstrehåndet eller lige god til at bruge venstre og højre hånd?
- Hvilken af dine tær er længst? Fx. storetåen eller nr. 2 tå.
- Har du fregner?
- Har du kløftet eller ikke kløftet hage?
Opgave 2
Denne øvelse laver I fælles i klassen – du skal bruge dine svar fra øvelse 1
Genetisk mutationer
Du har to kopier af hvert gen i dit DNA. Den ene kopi af genet har du arvet fra din mor og den anden fra din far. Har du en mutation, kan mutationen findes enten i den ene kopi eller i begge kopier af genet. Har du arvet mutationen fra begge forældre, har du altså den samme mutation i begge kopier af genet. I det datamateriale, du skal arbejde med, er mutationerne navngivet med rs efterfulgt af 8 tal. Hver række svarer til en person. Label angiver øjenfarve for personen. For hver person angives om mutationen findes i ingen (0), den ene (1) eller begge kopier (2) af genet. I den første opgave skal du undersøge, hvilke mutationer, som optræder oftere hos personer med blå øjne eller hos personer med brune øjne.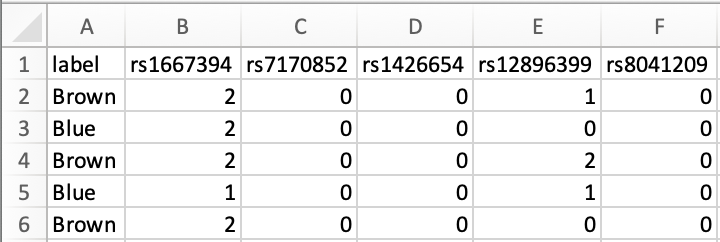
Opgave 1: indlæs DNA-data om mutationer, samt øjenfarve
Download først filen “gendata” til din computer. Åben et nyt workflow i programmet Orange.- Tilføj “CSV File Import” fra paletten “Data”
- Dobbelt klik “CSV File Import” og vælg filen “gendata.csv” – er vedhæftet nederst på denne side
- Vælg “Semicolon” ud for “Cell delimiter”
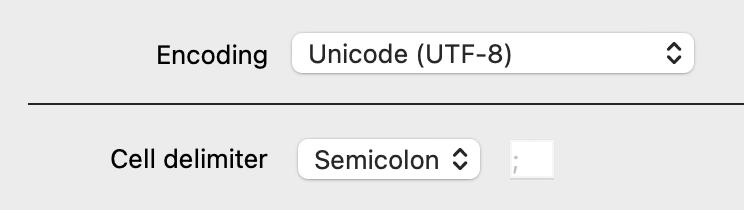
- Marker alle kolonner og vælg “Categorical” ud for “Column type”

- Klik ok
- Du kan altid komme tilbage til dette vindue ved at klikke på “Import Options…” i “CVS File Import“-vinduet.
- Husk at gemme dit workflow, så du ikke mister det, du har lavet
Opgave 2: Statistik over mutationer
- Tilføj “Distributions” fra paletten “Visualize”
- Forbind “CSV File Import” og “Distributions”
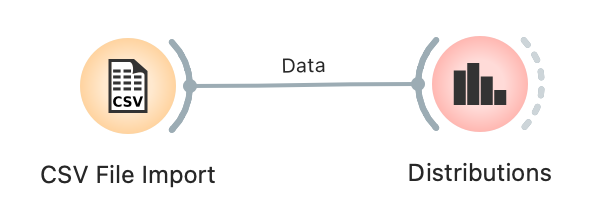
- Dobbelt klik på “Distributions”
- I Distributions-vinduet kan du undersøge fordelingen for antallet af mutationer for de forskellige gener. Her kan du se fordelingen for mutationen rs12913832. Der er lidt mere end 100 personer som har mutationen på begge kopier af genet, og lidt færre end 20 personer som ingen mutationer har på dette gen.
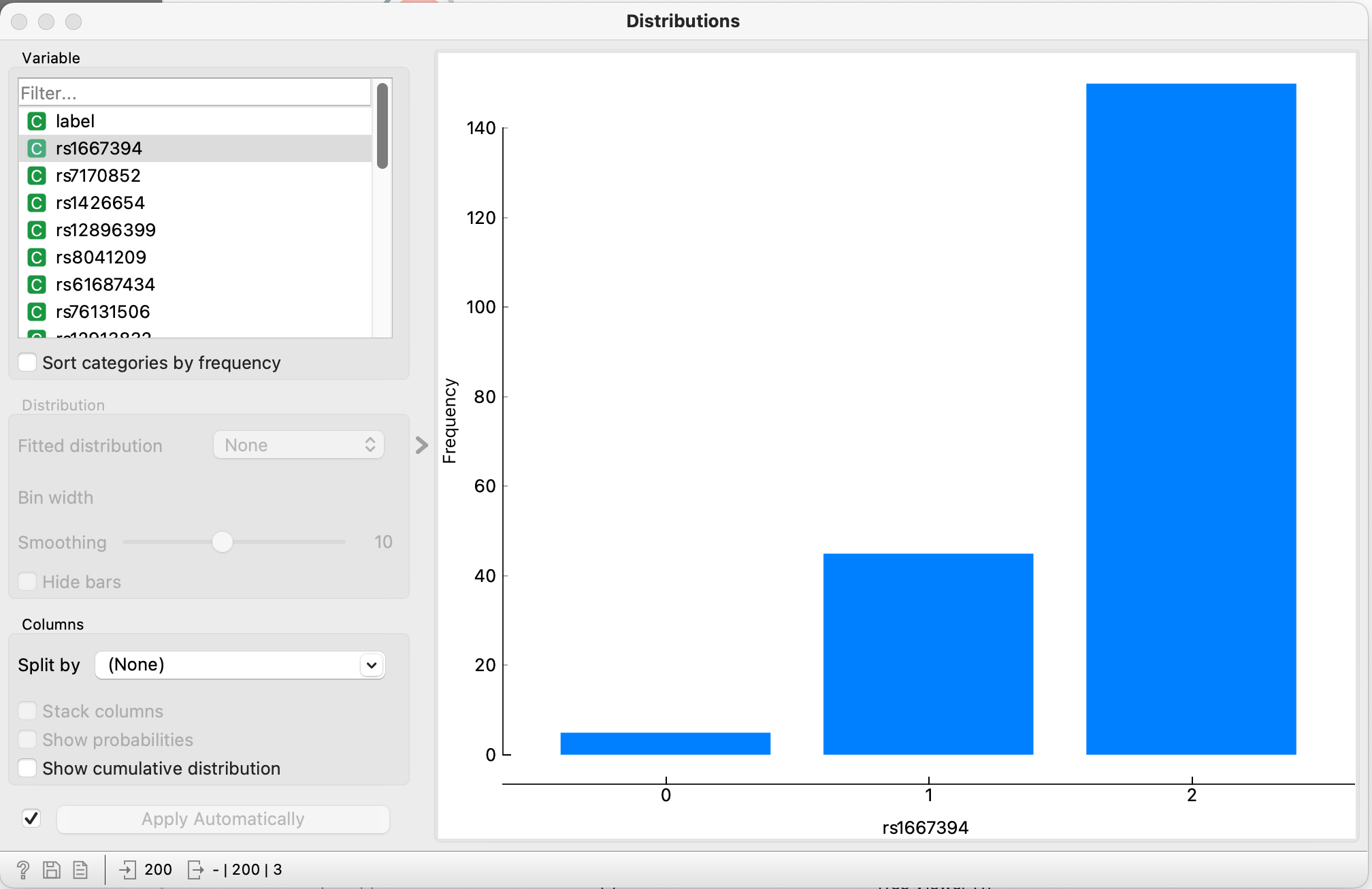
- Undersøg de forskellige mutationer på listen
Opgave 3: Sammenhængen mellem mutationer og øjenfarve
- Nederst i Distributions-vinduet sættes “Split by” til “label”
- Nu skal du undersøge alle mutationerne og se om mutationerne optræder forskelligt for de forskellige øjenfarver. Vælg én mutation, 1 efter 1, og noter de mutationer, hvor der er stor forskel på de 3 øjenfarver
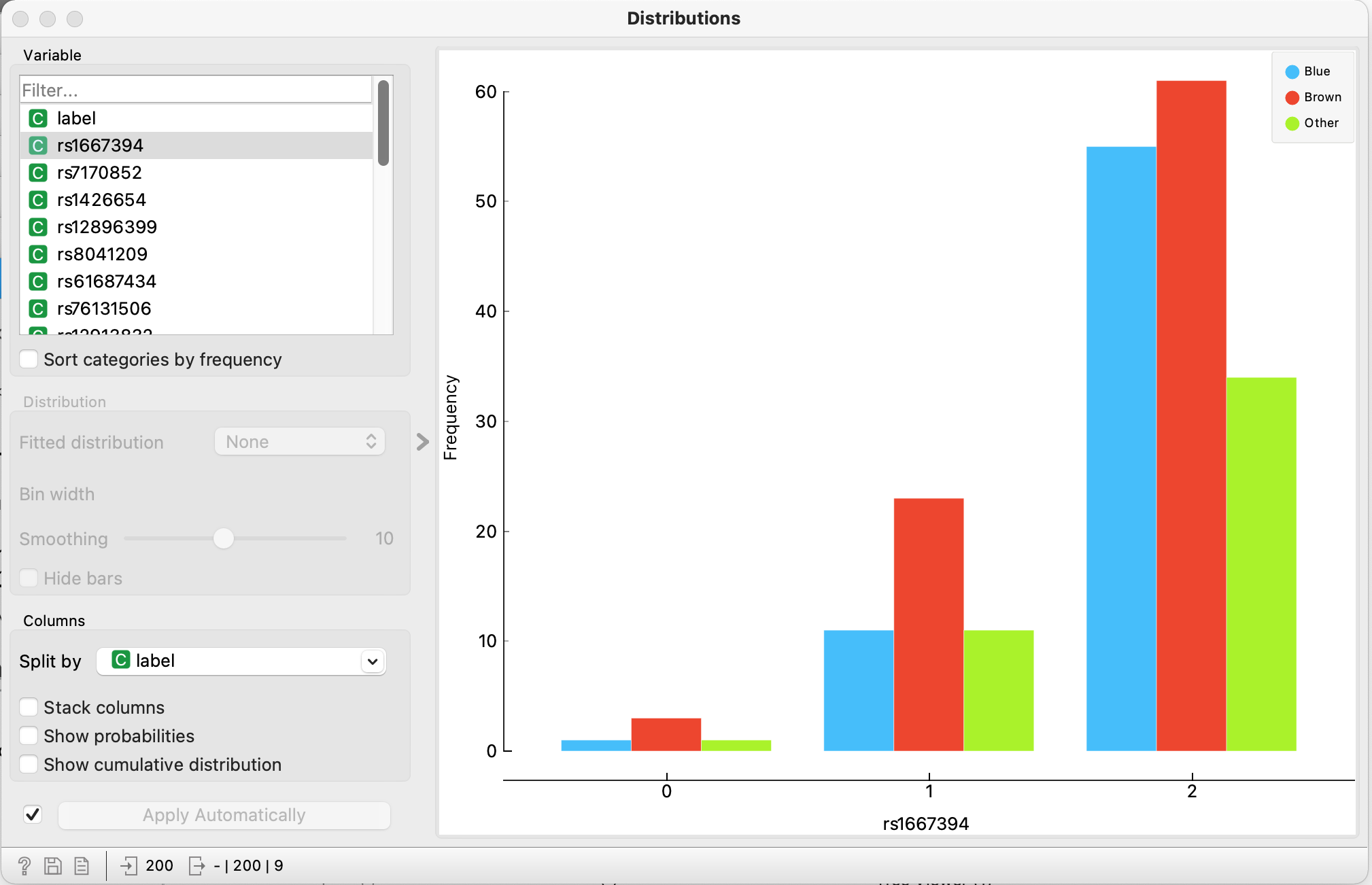
- Noter hvilke mutationer, der kan være med til at bestemme øjenfarven = er forskelligt fordelt – noter de 3 du synes ser mest betydningsfulde og diskuter jeres resultater i klassen
Forudsigelse af øjenfarve vha. DNA-spor
Først skal du træne en Machine Learning model, som du kan bruge til at forudse øjenfarve ud fra nye DNA-spor.Opgave: Træning af modellen
Åben dit workflow fra aktivitet “2.4 – Øjenfarve go mutationer”- Tilføj “Select Columns” fra paletten “Transform”
- Forbind “CSV File Import” og “Select Columns”
- Dobbelt klik på “Select Columns”
- I “Select Columns”-vinduet flyttes “label” til Target-feltet – dermed har du valgt at modellen skal trænes til at forudse øjenfarve – luk vinduet

- Tilføj “Tree” fra paletten “Model“
- Forbind “Select Columns” og “Tree”
Hvordan virker en træ-model
I 1. modul arbejdede du med ML-modellerne kNN og SVM. I dette modul bruger du Decision Tree (beslutningstræ). Det passer bedre til de data vi har her, da alle features har værdierne 0, 1 eller 2. Træ-modeller deler træningsdatasættet i mindre og mindre grupper, indtil alle eller næsten alle i gruppen har sammen label. Her deler vi ud fra mutationerne, indtil alle i en gruppe har samme øjenfarve. For hver mutation udregner træ-modellen, hvor stor procentdel der har brun, blå og anden øjenfarve. For rs12913832 kan du se i tabellen at både 0 og 1 mutation stort set kun forekommer for brun og anden øjenfarven. Godt halvdelen med 2 mutationer har blå øjne. Træ-modellen deler derfor personerne i 2 grupper. Dem med 0 og 1 mutation (mest brune og andet) , og dem med 2 mutationer (fleste med blå). Derefter undersøges de 2 grupper hver for sig. Og grupperne deles i mindre grupper vha. de mutationer for andre gener.| Øjenfarve | |||
|---|---|---|---|
| Antal mutationer for rs12913832 | Blå | Brune | Andet |
| 0 | 0% | 100% | 0% |
| 1 | 7,8% | 73,4% | 18,8 |
| 2 | 52,1% | 19,3% | 28,6% |
Illustration af Decision Tree
Træ-modellen vises som et omvendt træ, hvor man begynder øverst. I den øverst boks vises at 43,5% af de 200 personer i datasættet har brune øjne. Derefter deles datasættet ud fra mutationen rs12913832. Den ene gruppe består af 81 personer med 0 eller 1 mutation på rs12913832. Af dem har 79% brune øjne. Af de 119 med 2 mutationer har 52% blå øjne. Når man bruger modellen til forudsigelser, følger man træet fra top til bund. Hvis vi begynder med en person med 1 mutation på rs12913832, går vi til højre i træet. Da der står “Brown” på højre boks vil vi forudse at personen med 79% sikkerhed har brune øjne.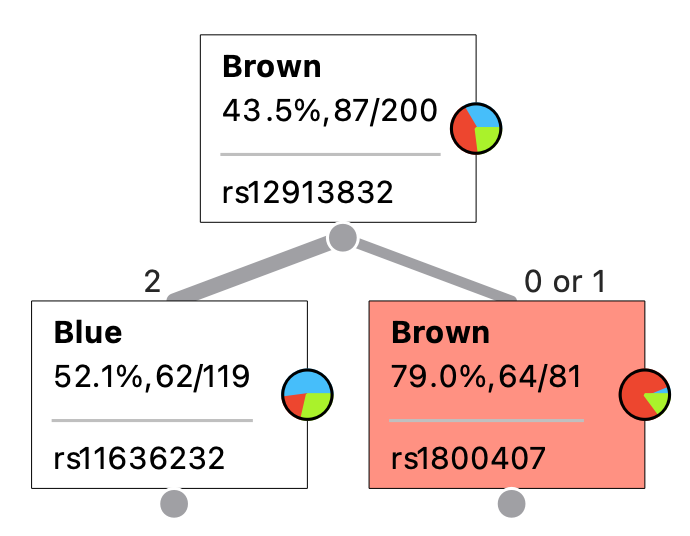
Tag et skærmbillede af dit workflow i Orange, hvor man kan se, hvordan dit program ser ud nu. Sæt billedet ind i dine noter, så du kan finde tilbage til hvordan programmet så ud, og du kan vise det til din lærer.

Forudsigelse af øjenfarve vha. DNA-spor
Nu skal du teste din Machine Learning model for at se, hvor god den er til at forudse øjenfarve ud fra DNA-spor.Opgave: test din Machine Learning model
- Tilføj “Predictions” fra paletten “Evaluate”
- Forbind “Select Columns” til “Predictions”
- Forbind “Tree” til “Predictions”
- Dobbelt klik på “Predictions” og undersøg, hvor god modellen er til at forud se øjenfarve – gør det samme som i aktivitet “1.2.6 – Test din ML-model” i 1. modul.
- Svar på spørgsmålene nedenfor ud fra “Predictions”-vinduet
- Hvilken øjenfarve forudser modellen for person nr. 1?
- Hvilken sikkerhed giver modellen for denne forudsigelse af øjenfarven for person nr. 1?
- Hvilken øjenfarve forudser modellen for person nr. 15?
- Hvilken sikkerhed giver modellen for denne forudsigelse af øjenfarven for person nr. 15?
- Er forudsigelsen for person nr. 15 korrekt?
Nu er du klar til at hjælpe politiet
Vi har 3 forskellige DNA-spor fra 3 forskellige forbrydelser. Du skal forudse øjenfarve i alle 3 sager og angive hvor sikker modellen er i forudsigelserne. Retsmedicinsk institut laver analyser for politiet. De kan f.eks. hjælpe politiet med at bestemme alder, øjen-, hår- og hudfarve, samt etnisk oprindelse. Når politiet afleverer et DNA-spor fra en gerningsmand til analyse, kan de få disse oplysninger om gerningsmandens udseende. Det er også vigtigt at beregne, hvor sikker modellen er i forudsigelsen af f.eks. øjenfarve. Hvis modellen er meget usikker på øjenfarven, kan politiet ikke bruge oplysningen som bevis i en retssag.Opgave: Bestem gerningsmandens øjenfarve
Vi vil bruge den trænede model til at forudse gerningsmændenes øjenfarver. Du har modtaget DNA-sporene i en csv-fil. Du kan downloade filen her: DNA_spor_farve. Du skal fortsætte i det workflow, du har lavet i 2.5.3- Tilføj “CSV File Import” fra paletten “Data”
- Dobbelt klik på “CSV File Import” og indlæs det DNAsporet i filen “DNA spor farve.csv” – husk at vælge “Semicolon” i “Cell delimiter” og “Categorial” i “Column Type”
- Tilføj “Select Columns” fra paletten “Transform”
- Forbind “CSV File Import” og “Select Columns”
- Dobbelt klik på “Select Columns”
- I “Select Columns”-vinduet flyttes alle DNA-data til Features-feltet
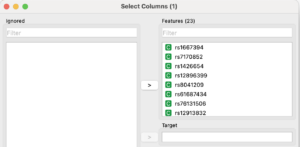
- Tilføj “Predictions” fra paletten “Evaluate”
- Forbind “Select Columns” til “Predictions”
- Forbind “Tree” fra den tidligere opgave til den nye “Predictions”
- Dobbelt klik på den nye “Predictions”
- I Predictions-vinduet skal du vælge “Classes known to the model”
 gøre Tree-kolonnen bredere så du kan se sandsynlighederne
gøre Tree-kolonnen bredere så du kan se sandsynlighederne - Hvilken øjenfarve forudser modellen for de 3 DNA-spor?
- Hvilke sandsynligheder angives for de 3 mulige øjenfarver?

White box og Black box modeller i Machine Learning
Nogle Machine Learning modeller kan vi undersøge og forstå, hvordan de når frem til et bestemt svar. Vi kalder dem White Box modeller. kNN og SVM modellerne fra 1. modul er White Box modeller, fordi vi kan undersøge placeringen af træningsdata i et koordinatsystem, og hvor de forskellige kategorier er placeret i koordinatsystemet. Neurale Netværk kan ikke analyseres på samme måde og vi kalder dem derfor for Black Box modeller. De bruges ofte til billedegenkendelse – f.eks. når computeren skal afgøre, om der er et ansigt på et foto. I dette modul bruger du Decision Tree (beslutningstræ). Det passer bedre til de data vi har her, da alle features har værdierne 0, 1 eller 2. Træ-modeller er også White Box. I træ-modellen deles data i grupper ud fra forskellige features, så man hver gang får delt træningsdata bedst muligt i forhold til de kategorier man skal forudse.Hvordan virker en træ-model?
Træ-modeller deler træningsdatasættet i mindre og mindre grupper, indtil alle eller næsten alle i gruppen tilhører samme kategori. Her deler vi ud fra mutationerne, indtil alle i en gruppe har samme øjenfarve. For hver mutation udregner træ-modellen, hvor stor procentdel der har brun, blå og anden øjenfarve. For rs12913832 kan du se i tabellen, at både 0 og 1 mutation stort set kun forekommer for brun og anden øjenfarven. Godt halvdelen med 2 mutationer har blå øjne. Træ-modellen deler derfor personerne i 2 grupper. gruppen med 0 og 1 mutation (mest brune og andet) , og gruppen med 2 mutationer (fleste med blå). Derefter undersøges de 2 grupper hver for sig. Og grupperne deles i mindre grupper vha. mutationer for andre gener.| Øjenfarve | |||
|---|---|---|---|
| Antal mutationer for rs12913832 | Blå | Brun | Anden |
| 0 | 0% | 100% | 0% |
| 1 | 7,8% | 73,4% | 18,8 |
| 2 | 52,1% | 19,3% | 28,6% |
Illustration af Decision Tree
Træ-modellen vises som et omvendt træ, hvor man begynder øverst. I den øverst boks vises at 43,5% af de 200 personer i datasættet har brune øjne. Derefter deles datasættet ud fra mutationen rs12913832. Den ene gruppe består af 81 personer med 0 eller 1 mutation på rs12913832. Af dem har 79% brune øjne. Af de 119 med 2 mutationer har 52% blå øjne. Når man bruger modellen til forudsigelser, følger man træet fra top til bund. Hvis vi begynder med en person med 1 mutation på rs12913832, går vi til højre i træet. Da der står “Brown” på højre boks vil vi forudse, at personen med 79% sikkerhed har brune øjne.Opgave 1: forstå hvilke gener som bruges i forudsigelsen af øjenfarven
Åben dit workflow fra aktivitet 2.5.4- Tilføj “Tree Viewer” fra paletten “Visualize”
- Forbind “Tree” og “Tree Viewer”
- Dobbelt klik på “Tree Viewer”
- I vinduet “Tree Viewer” kan du undersøge hvilke mutationer modellen bruger til at forudse øjenfarve.
De små cirkler viser fordelingen af øjenfarver i denne gruppe.
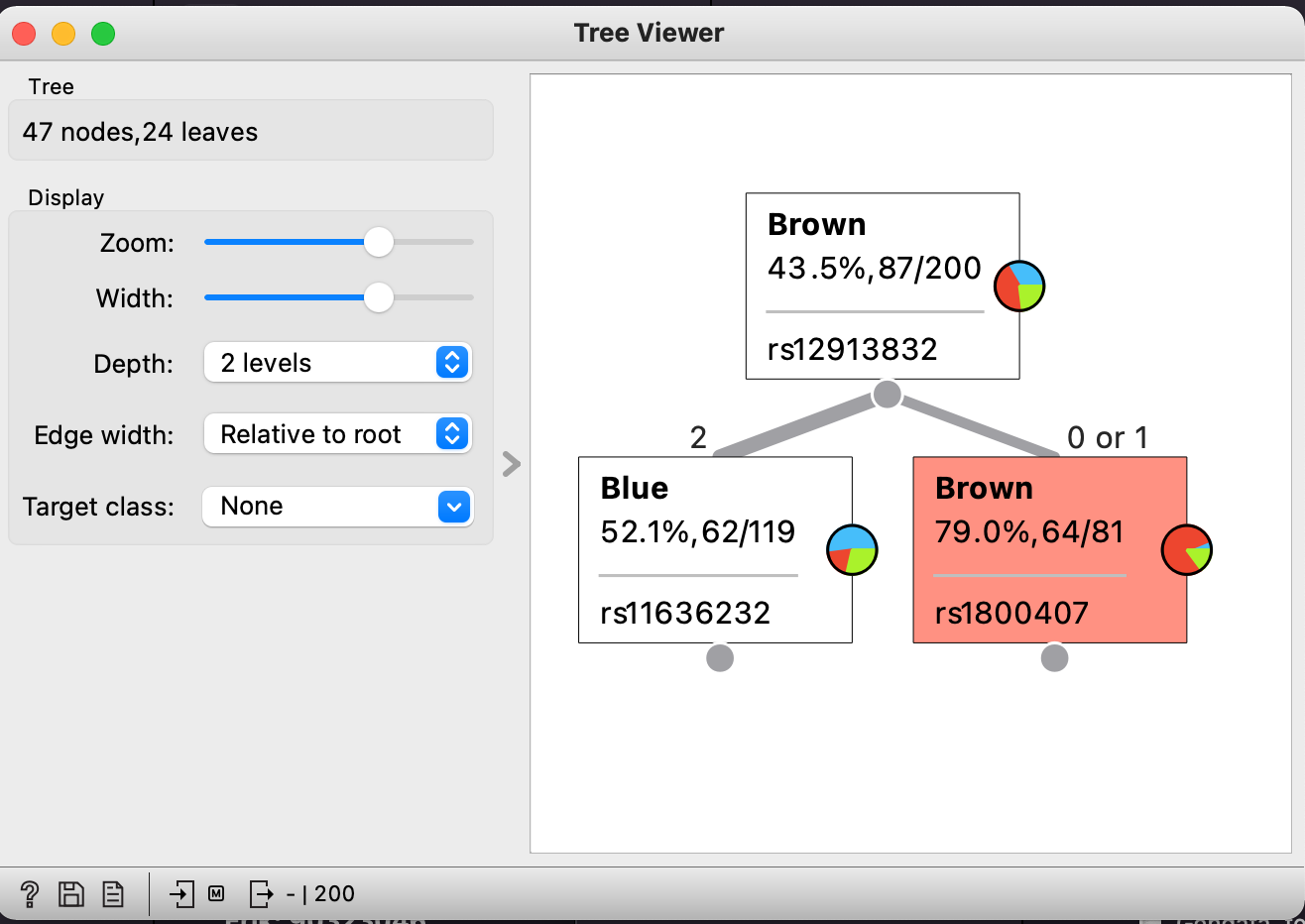
- Indstil Depth til “2 levels”.
- Hvilken mutationer bruger modellen til at forudse øjenfarven?
- Indstil Depth til “3 levels”.
- Hvilke ekstra mutationer bruger modellen nu til at forudse øjenforfarven?
Opgave 2
Om en person får du følgende information:- rs12913832 har 1 mutation
- rs11800407 har 2 mutationer
 Udvikling af ML-model til at bestemme en persons alder
Udvikling af ML-model til at bestemme en persons alder
Retsmedicinsk institut laver analyser for politiet. De kan f.eks. hjælpe politiet med at bestemme alder, øjen-, hår- og hudfarve, samt etnisk oprindelse. De udvikler løbende nye og bedre metoder. I dette modul skal du prøve at arbejde på samme måde og lave en ML-model til bestemmelse af alder ud fra DNA.
Matematikken sætter tal på, hvor god ML-modellen er
Politiet har brug for ML-modellen til at bestemme alder ud fra DNA f.eks. i sager hvor:
- et DNA-spor fra en forbrydelse kan bruges til at bestemme alder på den gerningsmand, som politiet leder efter
- en flygtning angiver at være under 18 år, men han kan ikke dokumentere det med en fødselsattest og man skal derfor bestemme alderen ud fra en blodprøve
I den første type sager kan politiet acceptere en større usikkerhed på aldersbestemmelsen (f.eks. ±5 år), mens aldersbestemmelsen for flygtninge skal være meget præcis, da der er stor forskel på de rettigheder børn og voksne har som flygtning og en alder under 18 år vil ofte være en fordel for den som søger asyl.
Retsmedicinerne skal bruge matematikken til at vise, hvor præcis deres ML-model er. Vi skal:
- beregne konfidensinterval for hældningen af en graf fra vores model
- lave analyse af residualerne for vores model
- beregne spredning af residualer for vores model
for at vise hvor god vores ML-model er.
I dette modul skal du
- repetere hvordan du importerer data til dit matematik program (Maple, Nspire eller hvad I bruger på din skole)
- repetere hvordan du laver almindelig lineær regression i dit matematik program
- lave en ML-model til aldersbestemmelse ud fra DNA-data
- lave lineær regression på resultaterne af ML-modellen og analysere residualerne
- beregne præcisionen af ML-modellen vha. spredningen af resultaterne
- beregne præcisionen af ML-modellen vha. konfidensinterval for hældning
- tolke præcisionen af ML-modellen, så du kan fortælle politiet, hvor god din model er
Problemer med afspilning af videoen: klik her
I denne video kan du se:
- hvordan DNA ændrer sig med alderen
- hvorfor man kan forudse en persons alder ud fra methylering af personens DNA

I disse opgaver skal du repetere regressionsanalyse og residualer
I disse opgaver skal du analysere sammenhængen mellem methyleringsgraden af området CCDC102B i personers DNA og alder for personerne.
Opgave 1: Lineær model til aldersbestemmelse
- Importer data fra filen “CCDC102B” til dit matematik program
- Undersøg om sammenhængen mellem metyleringsgrad og alder kan beskrives ved en lineær funktion \(f(x)=a \cdot x+b\)
- Bestem konstanterne \(a\) og \(b\) i modellen
- Forklar betydningen af konstanterne \(a\) og \(b\)
- I en DNA-prøve bestemmes methyleringsgraden for CCDC102B-området til 22,5. Beregn alderen for denne person vha. modellen
- En person er 20 år. Bestem vha. modellen methyleringsgraden for CCDC102B området svarende til denne alder.
Opgave 2: Analyse af residualer
Nu skal vi undersøge præcisionen af den lineære model ved at undersøge residualerne for datasættet og modellen
- Beregn residualerne for datasættet i filen “CCDC102B.xlsx” i forhold til modellen fra opgave 1.
Vis residualerne grafisk og kommenter hvad residualplottet viser om præcisionen af modellen. - For en af personerne i datasættet er methyleringsgraden 29 og personens alder er 50 år.
Beregn afvigelsen mellem den faktiske alder og modellens forudsigelse af alderen - Kommenter hvad residualer betyder for hvordan politiet kan bruge modellen til at bestemme alderen ud fra DNA-prøve med methyleringsgraden for CCDC102B-området.
I værktøjskassen kan du finde en video om import af data til Orange
Opgave 1: Hent data ind i Orange
- Download filen “Training” til din computer
- Tilføj “CSV File Import” til dit workflow – du finder ikonet til venstre i paletten “Data”
- Dobbelt klik på “CSV File Import” – klik derefter på mappen med de tre prikker
- Find filen “Training.csv” på din computer
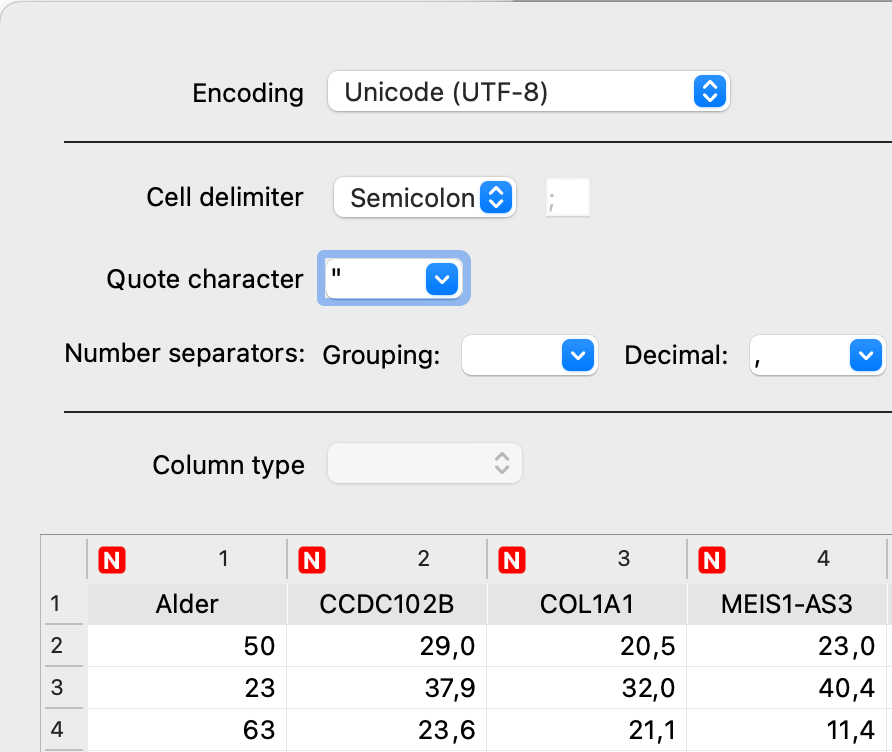
- Vælg “Semicolon” ud for “Cell delimiter” Data placeres nu i 8 kolonner Den første kolonne er alder for personerne. De 7 andre kolonner viser methyleringsgraden for 7 områder i DNA. De 7 områder er valgt, da de har en tydelig sammenhæng mellem alder og methyleringsgrad.
- Vælg komma ud for “Decimal” – den står ofte til punktum
- Marker alle kolonnerne og vælg “Numeric” ud for “Column type”
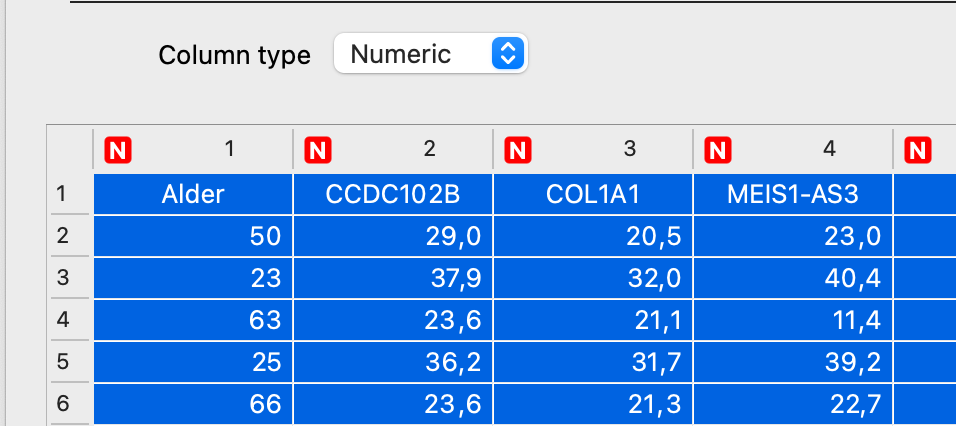
- Klik “Ok“
Opgave 2: Vis de importerede data
- Tilføj “Scatter Plot” fra paletten “Visualize”
- Forbind “CSV File Import” til “Scatter Plot”
- Dobbelt klik på “Scatter Plot” – nu kan du se data i et plot og vælge, hvordan du vil undersøge data.
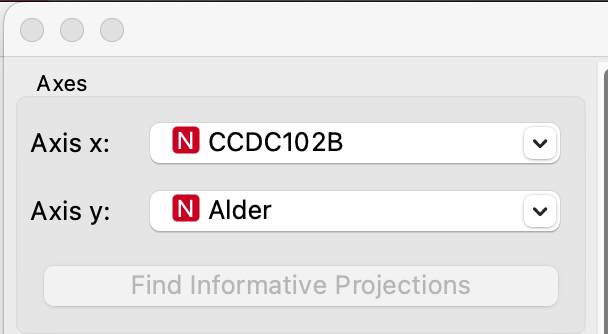 Vælg hvilke variable du vil vise på x- og y-aksen.
– Vælg “Alder” på y-aksen.
– På x-aksen vælges en af gangen de syv områder af DNA (CCDC102B, COL1A1, MEIS1-AS3, FHL2, IGSF11, PDE4C og ASPA).
Vælg hvilke variable du vil vise på x- og y-aksen.
– Vælg “Alder” på y-aksen.
– På x-aksen vælges en af gangen de syv områder af DNA (CCDC102B, COL1A1, MEIS1-AS3, FHL2, IGSF11, PDE4C og ASPA).- Undersøg hvilken af de 7 områder, du tænker vil være bedst til at forudse alder.
Opgave 3: Bestem hvilke data, du vil inkludere i ML-modellen
- Tilføj “Select Columns” fra paletten “Transform”

- Forbind “CSV File Import” til “Select Columns”
- Dobbelt klik på “Select Columns”
- Flyt “Alder” til “Target” – da det er alder, du vil forudse med modellen
- Flyt “CCDC102B” til “Features” – i første omgang bruger vi kun 1 område af DNA til ML-modellen.
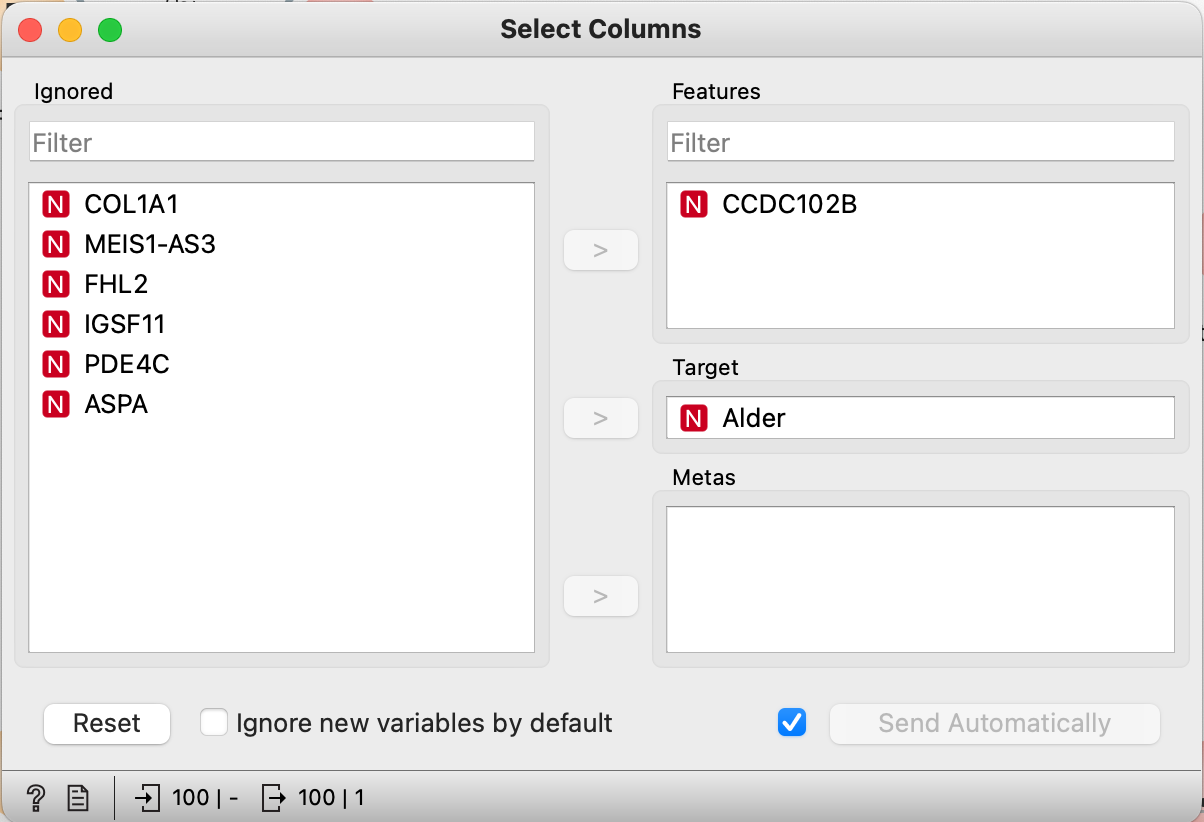
- Luk vinduet
Valg af Machine Learning model
I det første modul brugte du en kNN-model til at forudse køn ud fra højde og skostørrelse. Denne model egner godt, når vi skal forudse en kategori (kvinde/mand) ud fra egenskaber (features) med en numerisk værdi. I kNN-modellen udregnes afstande ud fra egenskaber angivet som reelle tal. I andet modul brugte du en træ-baseret model til at forudse øjenfarven ud fra antallet af mutationer på forskellige områder i DNA. Træ-baserede modeller egner sig godt til at forudse en kategori (brun/blå/andet øjenfarve) ud fra egenskaber, som også er kategorier, her 0, 1 eller 2 mutationer i hvert af DNA-områderne, som indgår i modellen. I dette modul skal vi forudse en værdi (alder) angivet som et reelt tal. Modellen skal bruge egenskaber som også angives som reelle tal, her methyleringsgraden. Derfor skal vi bruge en ny type ML-model: Lineær regression.ML-modellen “Linear Regression”
ML-modellen “Linear Regression” har samme navn, som den lineære regression du kender fra matematik, men som ML-model kan den noget mere. Den kan bl.a. bruge flere features samtidigt til at forudse alderen. Her vil vi ikke gå i dybden med hvordan modellen virker, da det vil være for omfattende. Du kan forestille dig, at det \(x\), som indgår i udtrykket \(y=a \cdot x + b\), består af flere variable på samme måde, som i funktioner af 2-variable \(f(x,y)\) – som du måske allerede kender fra undervisningen i Matematik A. For hver variabel er der en a-værdi.Opgave: Lav en simpel ML-model med “Linear Regression”
- Tilføj “Linear Regression” fra paletten “Model”
- Forbind “Select Columns” til “Linear Regression”
- Dobbelt klik på “Linear Regression” – sæt fluebenet ud for “Fit intercept”Dette er vigtigt – ellers låses skæringen med y-aksen til nul
– svarende til \(b\)-konstanten for den rette linje \(y=a \cdot x + b\) sættes til 0
Hvis fluebenet ikke er sat, virker modellen dårligt
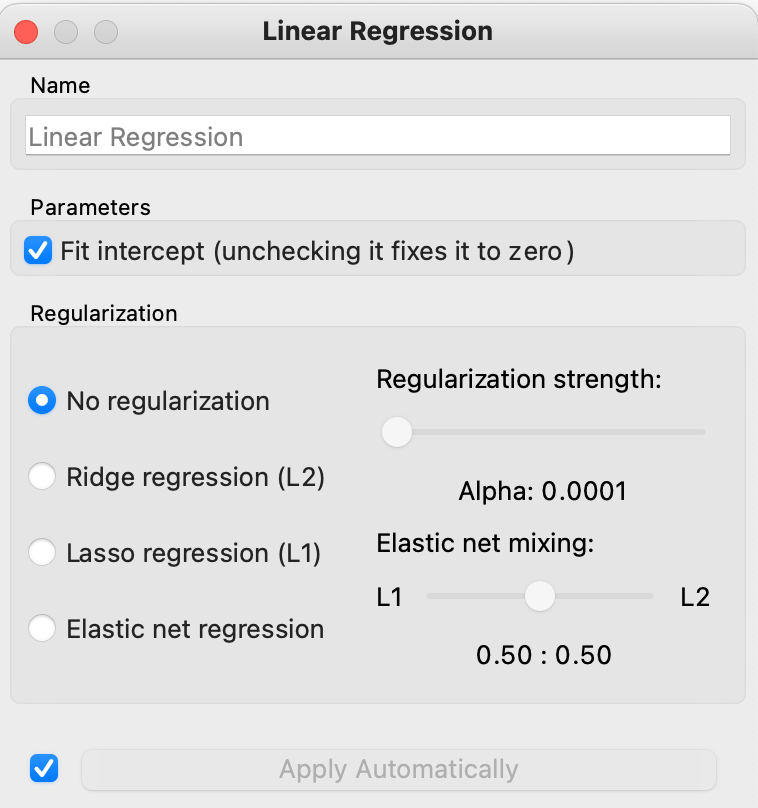
- De andre parametre bestemmer, hvordan modellens beregninger virker – vi kan bruge standard indstillingerne, så her skal du ikke ændre noget.
- Luk vinduet
Opgave 1: Forudse alder ud fra DNA-data
- Tilføj “Predictions” fra paletten “Evaluate” til dit workflow
- Forbind “Select Columns” til “Predictions”
- Forbind også “Linear Regression” til “Predictions“
- Dobbelt klik på “Predictions”
- Undersøg hvilken alder ML-modellen forudser, når vi kun har inkluderet data fra området “CCDC102B”
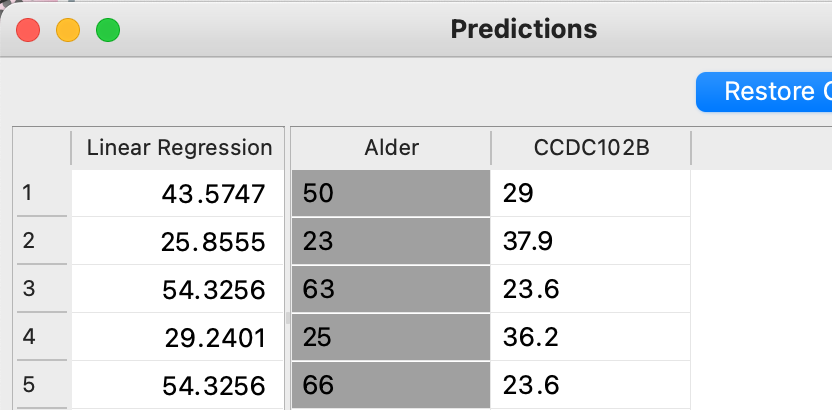 Forudsigelsen af alder finder du i kolonnen “Linear Regression”. Den faktiske alder for personen finder du kolonnen “Alder”.
Forudsigelsen af alder finder du i kolonnen “Linear Regression”. Den faktiske alder for personen finder du kolonnen “Alder”. - Hvor stor er den største afvigelse, du kan finde mellem faktisk alder og forudset alder?
Opgave 2: Vis resultatet af den simple ML-model
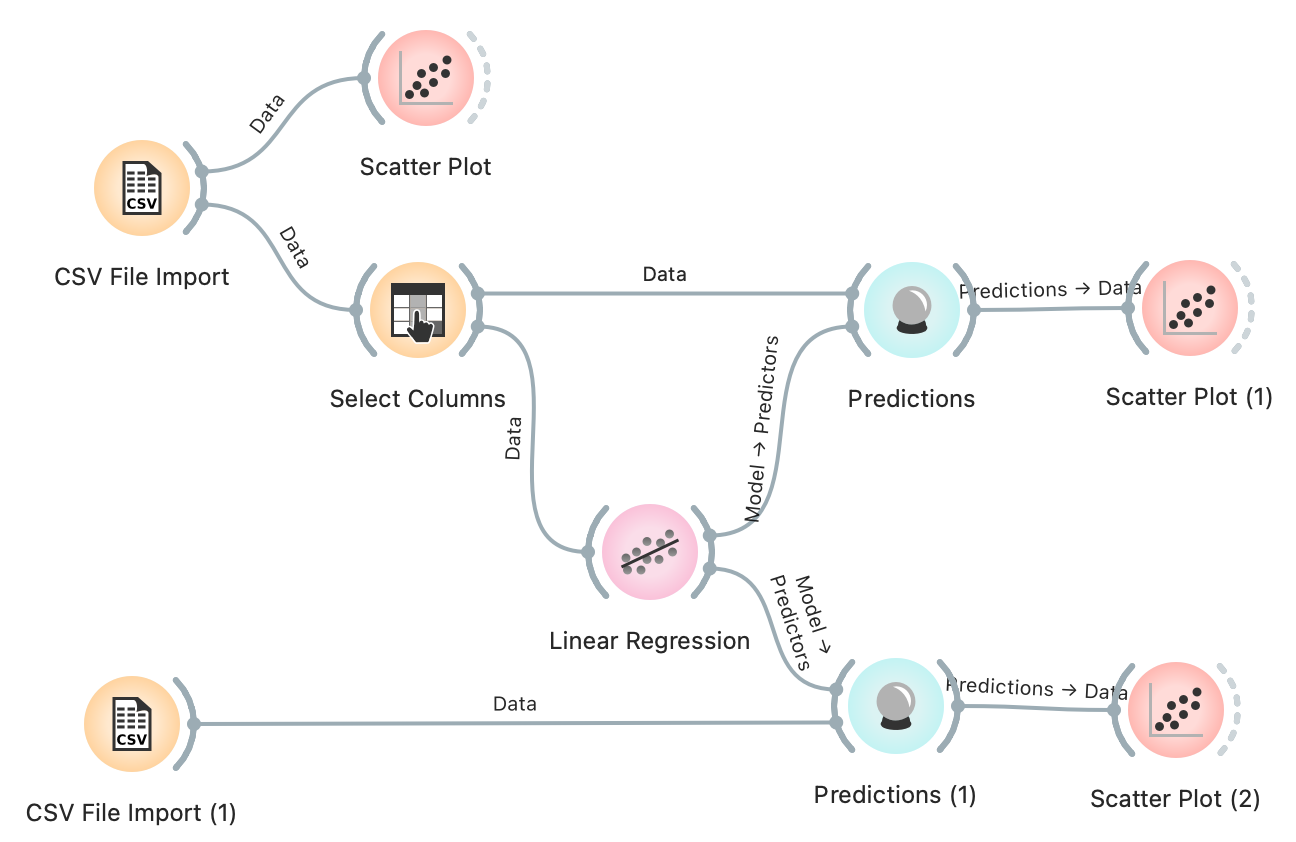
- Tilføj et “Scatter Plot” fra paletten “Visualize” til dit workflow
- Forbind “Predictions” til “Scatter Plot”
- Nu skal dit workflow se ud som på figuren
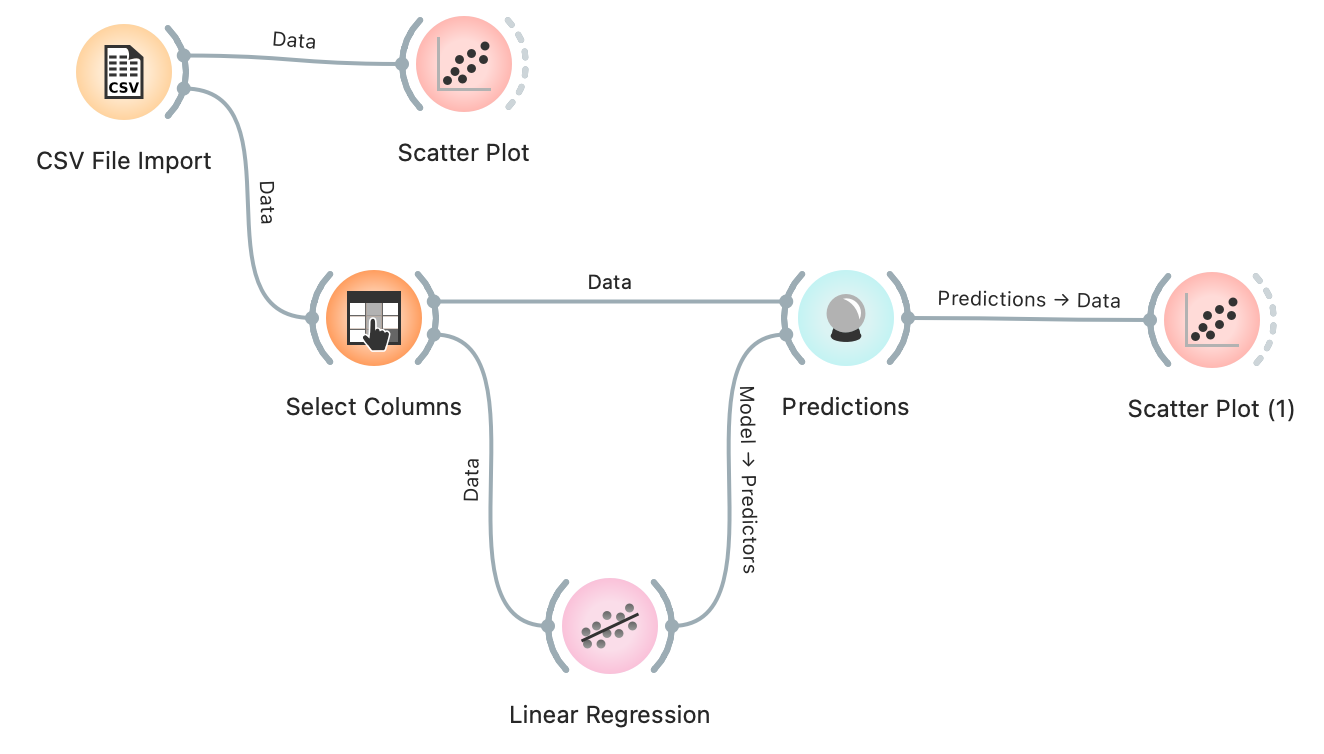
- Dobbelt klik på det nye “Scatter Plot” – vis den faktiske “Alder” på x-aksen og modellens forudsigelse “Linear Regression” på y-aksen.
- Sæt flueben ved “Show regression line”
 Den lille label på regressionslinjen viser korrelationskoefficienten r for grafen. Hvis der en perfekt lineær sammenhæng mellem faktisk alder og forudset alder, er \(r=1\). Hvis der ingen sammenhæng er vil vi få \(r=0\).
Den lille label på regressionslinjen viser korrelationskoefficienten r for grafen. Hvis der en perfekt lineær sammenhæng mellem faktisk alder og forudset alder, er \(r=1\). Hvis der ingen sammenhæng er vil vi få \(r=0\).
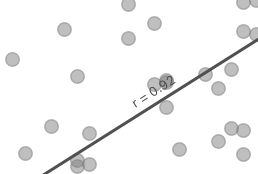
- Beskriv grafen for din model.
- Hvilken hældningen skal grafen have, hvis modellen er god til at forudse alder ud fra DNA-data?
- Hvordan skal punkterne være placeret i forhold til regressionslinjen, hvis modellen skal være præcis?

Test ML-modellen med et nyt sæt data
Når ML-modellen er trænet med et datasæt, skal modellen testes med et helt nyt datasæt. Man tester med et nyt datasæt for at vide, hvor godt modellen vil virke, hvis man skal bruge den rigtigt med DNA-data, som politiet har fundet på et gerningssted. Download filen “Validation” til din computer.Opgave 1: test modellen med validation-datasættet
Du skal arbejde videre med det workflow, du har lavet i aktivitet 3.3.3- Tilføj en ny “CSV File Import” fra paletten “Data”
- Hent filen “Validation.csv” ned på din computer
- Dobbelt klik på den nye “CSV File Import” og indlæs det nye datasæt ved at vælge filen “Validation.csv” – husk at vælge Semicolon, komma og Numeric, som i import af træningsdata.
- Tilføj en ny “Predictions” fra paletten “Evaluate”
- Forbind “Linear Regression” til den nye “Predictions“
- Forbind den nye “CSV File Import” til den nye “Predictions“
- Tilføj en ny “Scatter Plot” fra paletten “Visualize”
- Forbind den nye “Predictions” til det nye “Scatter Plot”
Sådan skal workflowet se ud, inden du går videre til næste opgave
Opgave 2: undersøg præcisionen i modellen
- Dobbelt klik først på “Scatter Plot (1)” og se undersøg, hvor godt modellen virkede med træningsdatasættet
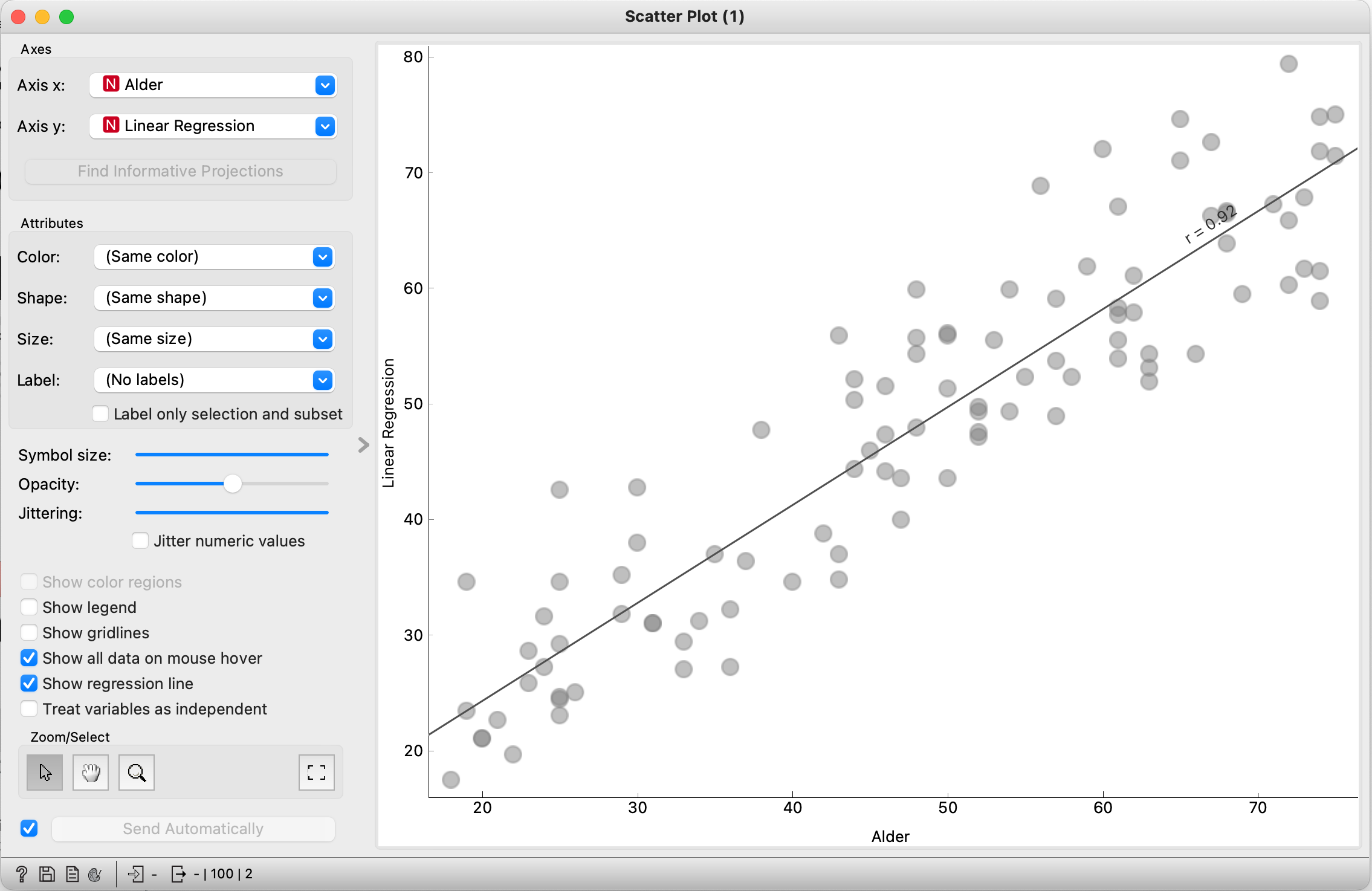
- Dobbelt klik derefter på “Skatter Plot (2)” og undersøg, hvor godt modellen virker med det nye valideringsdatasæt – er korrelationskoefficienten r den samme for trænings- og valideringsdatasættene?
- Ligger punkterne tættere på regressionslinjen eller mere spredt med det nye datasæt?
- Er hældningen af regressionslinjen tættere på den ønskede værdi med trænings- eller valideringsdatasættet?
Brug af flere DNA-områder i ML-modellen
Indtil videre har vi kun brugt methyleringsgraden i DNA-området CCDC102B til træning af ML-modellen. Nu vil vi forbedre modellen ved at træne ML-modellen med flere af de 7 DNA-områder, vi har data fra. Indtil nu har modellen svaret til det du lavede i aktivitet “3.2 – Lineær regression”Opgave 1: forbedring af ML-modellen
Brug det workflow du allerede har lavet.- Dobbelt klik på “Select Columns”
- Tilføj et DNA-området “COL1A1” til listen med egenskaber (Features), som modellen bruger i forudse alder. Luk vinduet igen.
- Dobbelt klik på “Scatter Plot (2)” og undersøg om modellen er blevet bedre ved at tilføje et ekstra DNA-område til modellen. Hvordan har hældningen af regressionslinjen ændret sig?
- Nu skal du tilføje flere DNA-områder til modellen og undersøge, om modellen bliver bedre til at forudse alderen.
- Virker modellen bedst, hvis du inkluderer alle DNA-områder i modellen?
- Er der et eller flere områder, du bør udelade i modellen?
- Sammenlign resultatet for træningsdatasættet i “Scatter Plot (1)” med resultatet for valideringsdatasættet “Scatter Plot (2)”

Analyse af ML-modellens præcision
Politiet har brug for at vide, hvor præcis din ML-model er, hvis de skal bruge modellen til at finde alderen på en gerningsmand ud fra et DNA-spor eller alderen på en flygtning, som søger asyl.
Hvis ML-modellen er god til at forudsige alder, vil der være lille forskel mellem alder og forudset alder for valideringsdatasættet, som vi arbejdede med i afsnit 3.3.5. Dvs. hældningen af grafen for den lineære model i “Scatter Plot” skal være \(a=1\) og konstantleddet \(b=0\).
For at analysere resultaterne fra ML-modellen bedre, skal data eksporteres og importeres i dit matematikprogram fx. Maple eller NSpire.
Hvad skal du:
- Eksportere forudsigelsen af alder fra Orange
- Importere forudsigelserne i dit matematikprogram fx. Maple eller Nspire
- Bestemme konfidensinterval for grafens hældning
- Undersøg residualerne for modellen

Opgave 1: eksporter data fra Orange
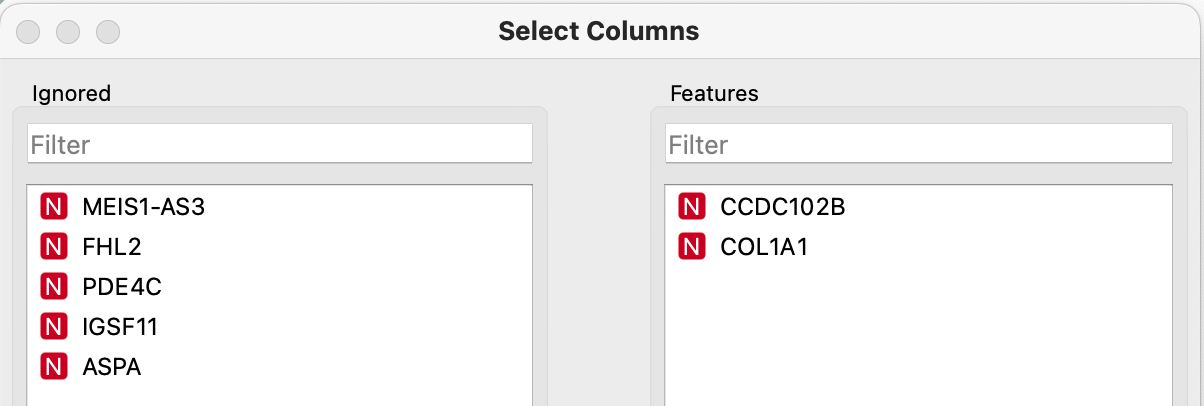
Åben dit workflow fra aktivitet 3.3.5- Tilføj “Select Columns” fra paletten “Transform”
- Forbind “Predictions (1)” til den nye “Select Columns”
- Dobbelt klik på den nye “Select Columns”
Vælg “Alder” og “Linear Regression”
- Luk vinduet
- Tilføj “Save Data” fra paletten “Data“
- Forbind “Select Columns (1)” til “Save Data”
- Dobbelt klik “Save Data”
Sæt flueben som vist på billedet:
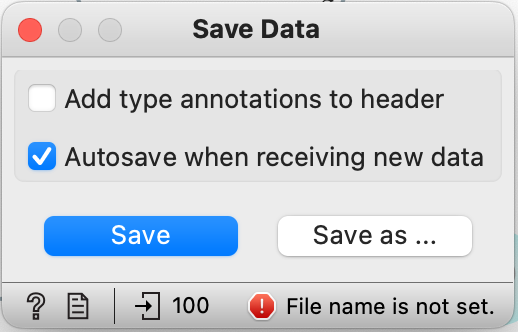
- Klik på “Save”
Giv filen et navn og vælg filformatet “Microsoft Excel spreadsheet (.xlsx)” fra menuen under filerne.
Husk at vælge en mappe, hvor du kan finde din fil.
- Find excel-filen på din computer. Åben filen. Den skal gerne ligne dette excelark
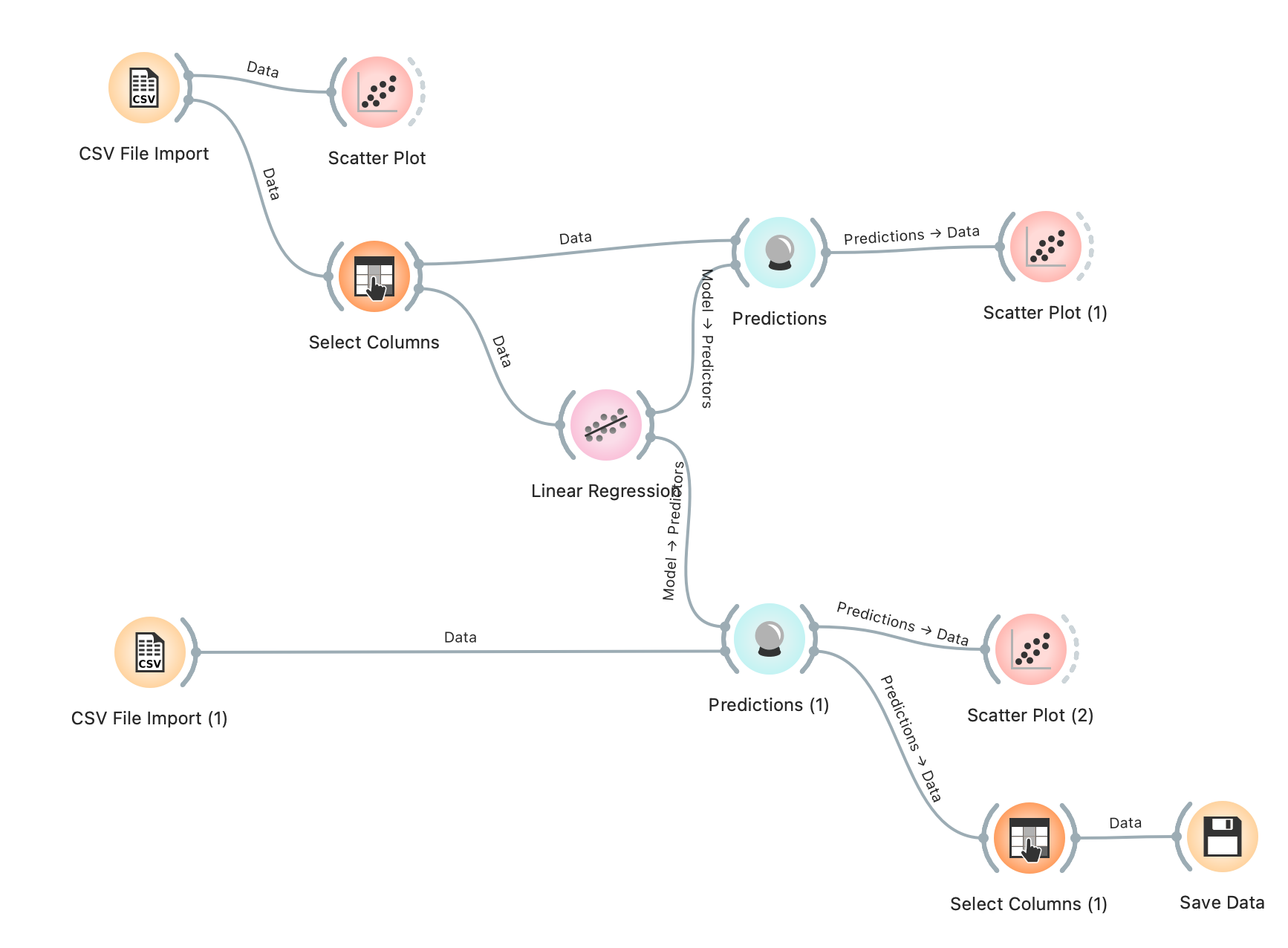
Dit workflow efter denne aktivitet

Opgave 1: Lineær regression på data fra ML-modellen
Nu skal du analysere resultatet af ML-modellens forudsigelse af alder
- Importer ML-modellens resultater, som du eksporterede i afsnit 3.4.1 ind i dit matematikprogram
- Undersøg om sammenhængen mellem alder og ML-modellens forudsigelse af alderen kan beskrives ved en lineær funktion \(f(x)=a \cdot x+b\)
- Bestem konstanterne \(a\) og \(b\) i modellen
- Forklar betydningen af konstanterne \(a\) og \(b\)
Ekstra opgave: Sammenlign med den simple ML-model
Du kan sammenligne den forberede model med den simple model ved at vælge færre DNA-områder i ML-modellen svarende til den simple ML-model i afsnit 3.3.2. Derefter eksporteres data fra Orange igen, og data analyseres i dit matematikprogram.
Problemer med videoen: klik her
Konfidensinterval for hældning
Når vi har lavet en ML-model til forudseelse af alder, vil vi gerne vide, hvor præcis modellen er.
Vi vil gerne have en lineær model:
\(forudset\ alder = 1 \cdot alder +0\)
dvs. hældningen skal være 1 og b-konstanten skal være 0
I videoen kan du se, hvordan man kan lave konfidensintervaller for a- og b-konstanterne i den lineære model, og teste om hældningen er som ønsket.
Opgave 1: konfidensinterval for hældningen af grafen i den lineære regression
Arbejd videre med data i dit matematikprogram
- Bestem 95%-konfidensintervallet for hældningen af grafen, dvs. find den øvre og nedre grænse for hældningen
- Test hypotesen \(a=1\). Bestem p-værdien i denne test og forklar, hvad resultatet betyder.
Ekstra opgave: Sammenlign med den simple ML-model
Du kan sammenligne den forberede model med den simple model ved at vælge færre DNA-områder i ML-modellen svarende til den simple ML-model i afsnit 3.3.2. Derefter eksporteres data fra Orange igen, og data analyseres i dit matematikprogram.
Problemer med videoen: klik her
Residualerne bør være normalfordelte
I en god ML-model vil afvigelserne mellem alderen og ML-modellens forudsigelse af alderen være normalfordelt. I videoen kan du se, hvordan man kan analysere det.
I opgaverne skal du arbejde videre med den lineære regression fra afsnit 3.4.3.
Opgave 1: plot residualerne for den lineære model
- Lav et plot af residualerne for den lineære model
- Hvor stor er den største afvigelse mellem modellen og den forudsete alder?
- Er der en systematik i residualerne?
- Hvor stor er residualspredningen s?
- Hvor stor en andel af residualerne ligger indenfor for intervallet [-1 s; 1 s] ?
- Hvor stor en andel af residualerne ligger indenfor for intervallet [-2 s; 2 s] ?
- Passer procenterne fra spørgsmål 5 og 6 med det man forventer for en normalfordeling?
Opgave 2: undersøg om residualerne er normalfordelte
- Lav et QQplot for residualerne fra den lineære model
- Er residualerne tilnærmelsesvis normalfordelte?
- Hvilke afvigelser er der fra normalfordelingen?

Rådgivning til politiet
I rådgivningen af politiet skal vi fortælle politiet, hvor præcist vi kan bestemme alderen på en person. Har vi forudset en alder på 24 år, skal vi bestemme et interval for personens alder. Billedet viser en model, hvor vi kun bruger methyleringsgraden for nogle af DNA-områderne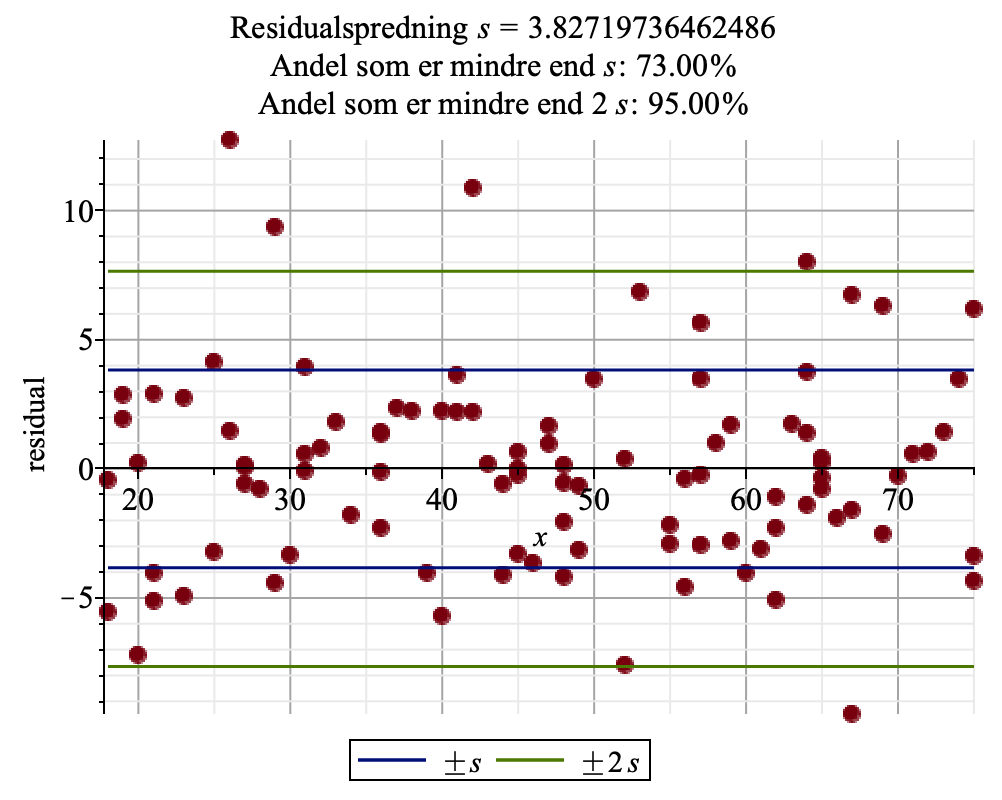
Interval for personens alder
Vi kan se, at spredningen er 3.8. Hvis residualerne er tilnærmelsesvis normalfordelte, kan vi tillade os at antage, at 95,5% af datasættet vil ligge indenfor 2 spredninger fra modellen. I svaret til politiet kan vi skrive, at vi med 95,5% sandsynlighed kan fastslå, at personens alder er i intervallet [25 år – 2·3.8 år; 25 år + 2·3.8 år] = [17.4 år; 32.6 år]. I dette tilfælde kan vi altså ikke afvise at personen er under 18 år. Hvis vi kan forbedre vores model, kan vi opnå en mindre spredning og derved et mindre aldersinterval i rådgivningen af politiet. De bedste modeller kan bestemme alderen med en spredning på ca. 1 år.Opgave 1: rådgiv politiet vha. jeres model
- Bestem spredning i den bedste udgave af din ML-model.
- Angiv et aldersinterval for en person, hvor din ML-model forudser en alder på 25 år